1032
Rsync is reportedly causing backups to fail since maintainer began AI code experiment
(files.catbox.moe)
"We did it, Patrick! We made a technological breakthrough!"
A place for all those who loathe AI to discuss things, post articles, and ridicule the AI hype. Proud supporter of working people. And proud booer of SXSW 2024.
AI, in this case, refers to LLMs, GPT technology, and anything listed as "AI" meant to increase market valuations.
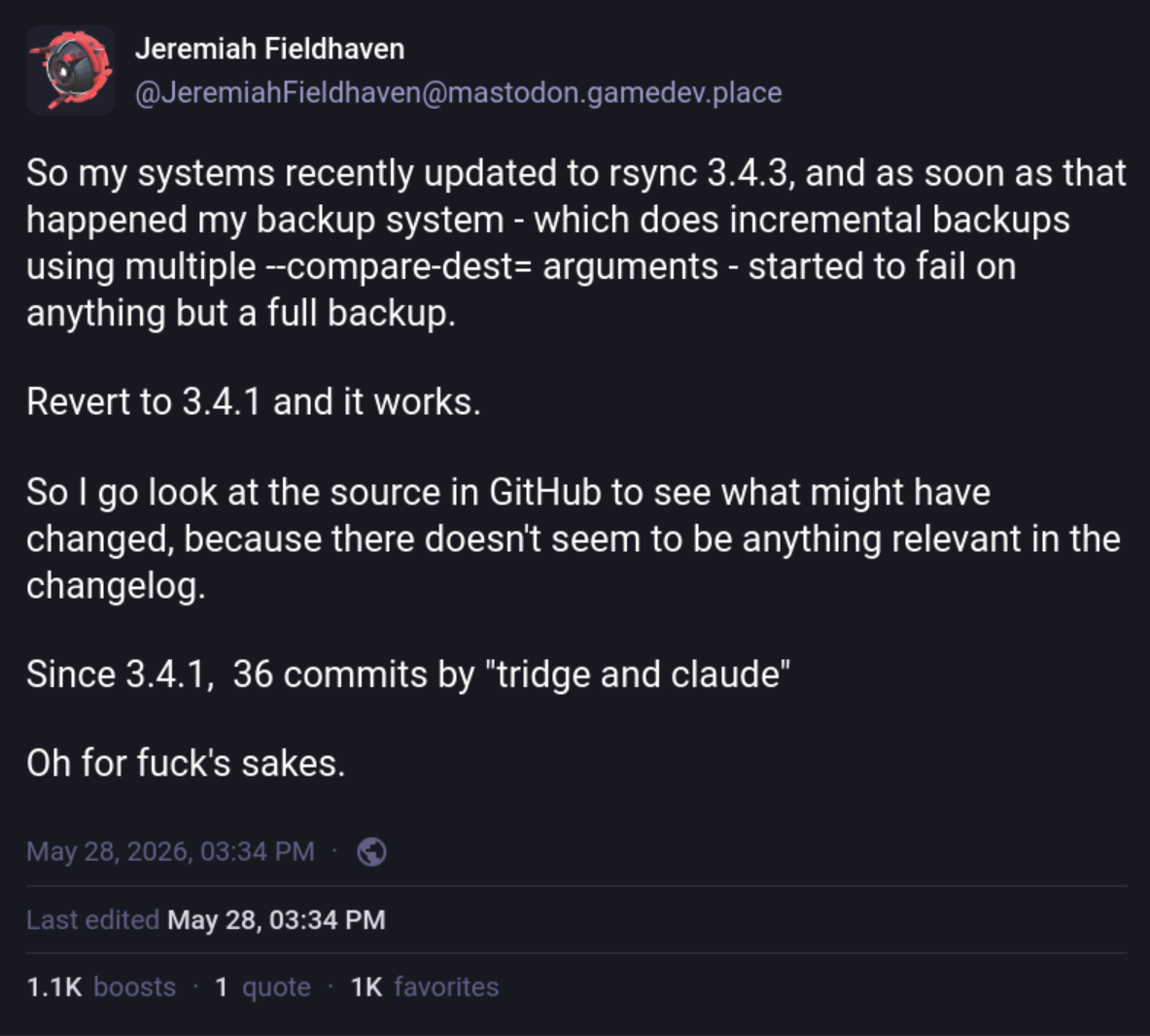
The project's issue tracker has been pretty wild recently, for example https://github.com/RsyncProject/rsync/issues/929
God both sides are toxic AF and here I am simply want to know if correlation is causation.
It is. Reading thus lemmy threads gives commits or links to other commenters. My fav is this one https://neuromatch.social/@jonny/116666900898570791
That's a great post, that well displays the issues with AI tests! For my own personal curiosity I looked at the testing rewrite of rsync, specifically the chgrp_test because it was the smallest test I quickly found. If you look at the original shell script, all it does is call chgrp and then fail if it doesn't work. In the Python rewrite on the other hand the LLM calls chown to change the group and only if that fails, it tests chgrp. So if for some reason chown works but chgrp would fail, the original shell script would easily catch that (cause why do you test for chown anyways) while the Python rewrite doesn't even call chgrp in case chown works.
Even though, this might not be as much of a problem in practice, I think it illustrates that the AI tends to write tests where it already anticipates and tries to fix potential issues, which absolutely goes against the use of tests!
dont get tricked into thinking an LLM can encode "anticipation of a potential issue"
LLMs just generate "statistically probable" text, all it's doing is generating text that looks like how you'd write tests, they may or may not actually test anything.
Lol this is hilarious! I want to see the prompt they used cause my god they didn't think it through
I'm honestly not seeing two sides being shitty. I feel like I see people being shitty towards the developer and people being opposed to that.