
It's completely bonkers that JPEG-XL is as good as it is and no one wants to actually implement it into web browsers
this post was submitted on 02 Sep 2024
0 points (50.0% liked)
Programming
27384 readers
59 users here now
Welcome to the main community in programming.dev! Feel free to post anything relating to programming here!
Cross posting is strongly encouraged in the instance. If you feel your post or another person's post makes sense in another community cross post into it.
Hope you enjoy the instance!
Rules
Rules
- Follow the programming.dev instance rules
- Keep content related to programming in some way
- If you're posting long videos try to add in some form of tldr for those who don't want to watch videos
Wormhole
Follow the wormhole through a path of communities !webdev@programming.dev
founded 3 years ago
MODERATORS
What's so good about it?
- Existing JPEG files (which are the vast, vast majority of images currently on the web and in people's own libraries/catalogs) can be losslessly compressed even further with zero loss of quality. This alone means that there's benefits to adoption, if nothing else for archival and serving old stuff.
- JPEG XL encoding and decoding is much, much faster than pretty much any other format.
- The format works for both lossy and lossless compression, depending on the use case and need. Photographs can be encoded in a lossy way much more efficiently than JPEG and things like screenshots can be losslessly encoded more efficiently than PNG.
- The format anticipates being useful for both screen and prints. Webp, HEIF, and AVIF are all optimized for screen resolutions, and fail at truly high resolution uses appropriate for prints. The JPEG XL format isn't ready to replace camera RAW files, but there's room in the spec to accommodate that use case, too.
It's great and should be adopted everywhere, to replace every raster format from JPEG photographs to animated GIFs (or the more modern live photos format with full color depth in moving pictures) to PNGs to scanned TIFFs with zero compression/loss.
Existing JPEG files (which are the vast, vast majority of images currently on the web and in people’s own libraries/catalogs) can be losslessly compressed even further with zero loss of quality. This alone means that there’s benefits to adoption, if nothing else for archival and serving old stuff.
Funny thing is, there was talk on the Chrome bug tracker of using just this ability transparently at the HTTP layer (like gzip/brotli compression), but they're so set on pushing their AVIF format that they backed away from it.
- The format works for both lossy and lossless compression, depending on the use case and need. Photographs can be encoded in a lossy way much more efficiently than JPEG and things like screenshots can be losslessly encoded more efficiently than PNG.
Someone made a fair point that having a format being both lossy and lossless is not necessarily a great idea. If you download a jpeg file you know it will be compressed, if you download png it will be lossless. Shifting through jxl files to check if it's lossy or not doesn't sound very fun.
All in all I'm a big supporter of jxl though, it's one of the only github repos I actively follow.
Functionally speaking, I don't see this as a significant issue.
JPEG quality settings can run a pretty wide gamut, and obviously wouldn't be immediately apparent without viewing the file and analyzing the metadata. But if we're looking at metadata, JPEG XL reports that stuff, too.
Of course, the metadata might only report the most recent conversion, but that's still a problem with all image formats, where conversion between GIF/PNG/JPG, or even edits to JPGs, would likely create lots of artifacts even if the last step happens to be lossless.
You're right that we should ensure that the metadata does accurately describe whether an image has ever been encoded in a lossy manner, though. It's especially important for things like medical scans where every pixel matters, and needs to be trusted as coming from the sensor rather than an artifact of the encoding process, to eliminate some types of error. That's why I'm hopeful that a full JXL based workflow for those images will preserve the details when necessary, and give fewer opportunities for that type of silent/unknown loss of data to occur.
Adobe is backing the format, Apple support is coming along, and there are rumors that Apple is switching from HEIC to JPEG XL as a capture format as early as the iPhone 16 coming out in a few weeks. As soon as we have a full blown workflow that can take images from camera to post processing to publishing in JXL, we might see a pretty strong push for adoption at the user side (browsers, websites, chat programs, social media apps and sites, etc.).
Do you know QOI format ? I would appreciate your opinion about it.
QOI is just a format that's easy for a programmer to get their head around.
It's not designed for everyday use and hardware optimization like jpeg-xl is.
You're most likely to see QOI in homebrewed game engines.
ISO 8601 date format. Not because it's from a standards body, but because it's simple, sensible, clearly defined, easy to recognize, and very effective.
Date field placement in any order other than most-significant-digits-first is not only counterintuitive, but needlessly complicated to work with. Omitting critical information like the century is ambiguous and confusing.
We don't live in isolated villages any more. Mixing and matching those problems by accepting all the world's various regional and personal date styles, especially with no reliable indication of which ones apply in any given case, leads to the hodgepodge of error-prone date madness that we have today.
The 2024-09-02 format should be taught in schools and required in official documents. Let the antiquated date styles fall into disuse outside of art and personal correspondence, like cursive writing.
And it can be sorted alphabetically in all software. That's a pretty big advantage when handling files on a computer
I'll give my usual contribution to RSS feed discourse, which is that, news flash! RSS feeds support video!
It drives me crazy when podcasters are like, "thanks for listening to our audio podcasts. We also have a video feed for our YouTube subscribers." Just let me have the video in PocketCasts please!
I wish standards were always open access. Not behind a 600 dollar paywall.
When it is paywalled I'm irritated it's even called a standard.
ActivityPub :) People spend an incredible amount of time on social media—whether it be Facebook, Instagram, Twitter/X, TikTok, and YouTube—so it’d be nice to liberate that.
I mean, you're in the right place to advocate for that 😜
PGP or GPG, however you spell it. You can encrypt stuff, protect your email from prying eyes!
Also FOSS in general.
I don't use XMPP but it seems like such a no-brainer
The metric system, f*ck the imperial system. Every scientist sticks to the metric system, and why are people even still having an imperial system, with outdated measurements like stones for weight blows my mind.
Also f*ck Fahrenheit, we have Celsius and Kalvin for that, we don't need another hard to convert temperature measurement.
You are allowed to say fuck here.
Also f*ck Fahrenheit, we have Celsius and Kalvin for that,
Who is Kalvin? Did you mean kelvin?
One drawback of celsius/centigrade is that its degrees are so coarse that weather reports / ambient temperature readings end up either inaccurate or complicated by floating point numbers. I'm on board with using it, but I won't pretend it's strictly superior.
A degree Celsius is not coarse and does not require decimals in weather reports, and I suspect only a person who has never lived in a Celsius-using country could make such silly claims.
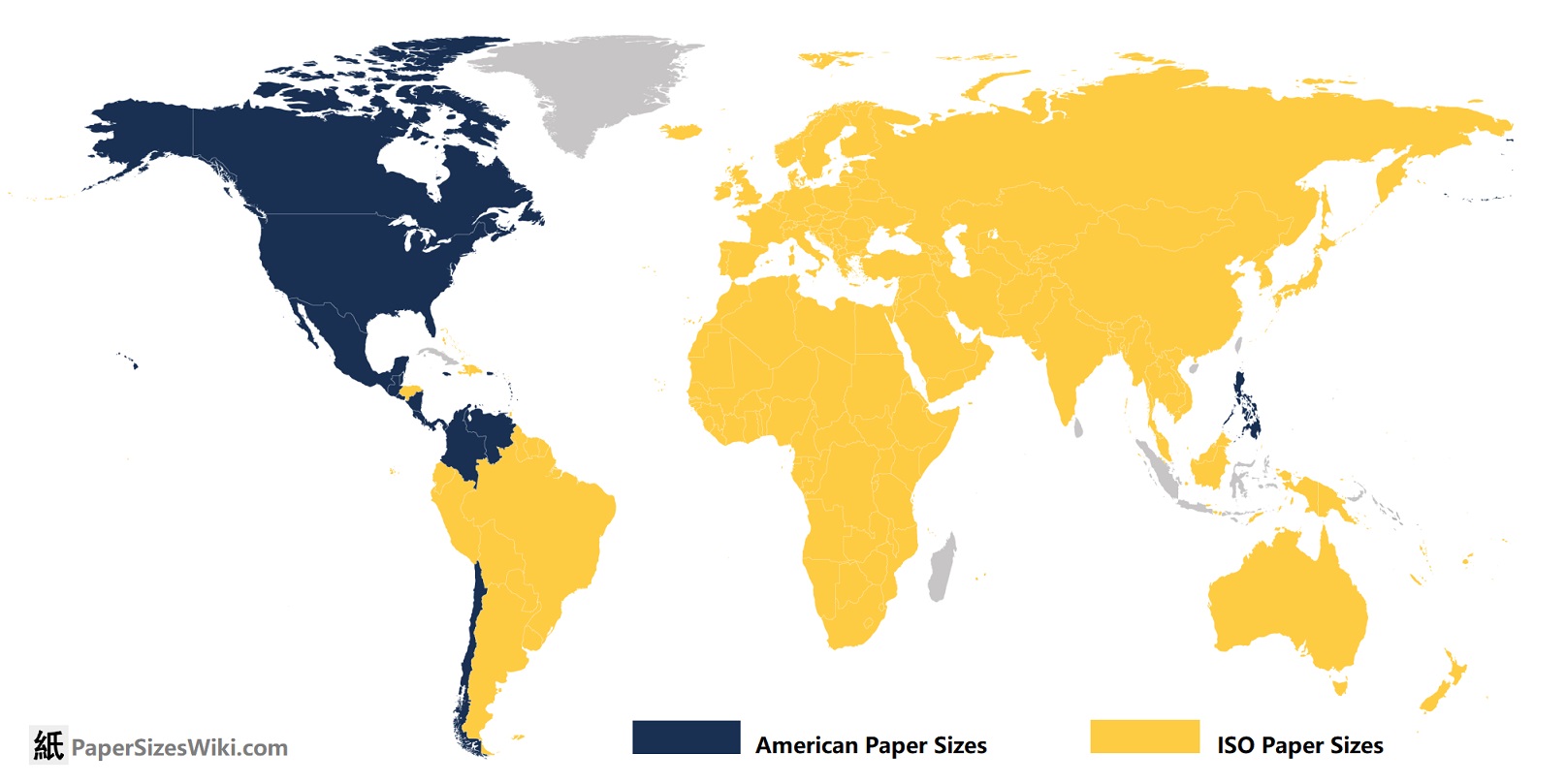
ISO 216 paper sizes work like this: https://www.printed.com/blog/paper-size-guide/
It's so fucking neat and intuitive! How is it not used more???
sorry to tell you this bud...
Zigbee or really any Bluetooth alternative.
Bluetooth is a poorly engineered protocol. It jumps around the spectrum while transmitting, which makes it difficult and power intensive for bluetooth receivers to track.
The term open-standard does not cut it. People should start using "publicly available and sharable" instead (maybe there is a better name for it).
ISO standards for example are technically "open". But how relevant is that to a curious individual developer when anything you need to implement would require access to multiple "open" standards, each coming with a (monetary) price, with some extra shenanigans ^[archived]^ on top.
IETF standards however are actually truly open, as in publicly available and sharable.
how about FOSS, free and open-source standards /s
I wish there was a good open standard for task management or todo list.
I know there's todo.txt, but it lacks features like dependent tasks, and overall the plain text format limits features and implementations.
IRC.
Jabber.
IPFS.
GRPC for building APIs instead of REST. Type safety makes life easier
IPv6. Stop engineering IoT junk on single-stack IPv4, you dipshits.
Ogg Opus. It's superior to everything in every way. It's free and there is absolutely no reason to not support it. It blows my mind that MPEG 1.0 Layer III is still so dominant.
i'm a plan 9 from bell labs fan. Imagine how excited I was when wsl used 9P for its plumbing. then they scrapped it all for wsl2.
just, the power they managed to get out of those union mounts... your application wants access to the mouse? sure, here's a file named "mouse". it's got the coordinates in it. you want to draw to the screen? here's a file called like "bitmap" or whatever, just write to it. you want to start a process on another machine? just cd to it and start the process there. want to have the UI show up on your machine? symlink your bitmap file to that directory.
I also wish early web composability could have stayed and expanded. like, the old vlc embed player, which would just show up in your browser and could play any file inline? great stuff. Imagine if every application composed with everything else, like the android Activity and Intent concepts but for anything, just by virtue of living in the same os. need an image? just ask the os and it will present the user with many ways to procure an image, let the selected one run , and hand you back an image. you don't even have to care where from. in a way, it's what the arcan guy is doing with his experiments, although that's more for stitching together graphical pipelines.
Plan 9 even extended the "everything is a file" philosophy to networking, unlike everybody else that used sockets instead.
Are sockets not files?
They're "file like" in the sense that they're exposed as an fd, but they're not exposed via the filesystem at all (Unlike e.g. unix sockets), and the existing API is just mapped over the sockets one (i.e. write() instead of send(), read() instead of recv()). There's also a difference in how you create them, you open() a file, but connect() a socket, etc.
(As an aside, it turns out Bash has its own virtual file-based wrapper around sockets, so you can do things like cat a remote port with Bash, something you can do natively in Plan 9)
Really it just shows that "everything is a file" didn't stand up in practice, there's more stuff that needs special treatment than doesn't (e.g. Interacting with TTYs also has special APIs). It makes more sense to have a better dedicated API than a generic catch-all one.
JSON5. it's basically just JSON with several QoL improvements, like comments, that make it usable as a format for human consumption (as opposed to a serialization format).
Objects may have a single trailing comma.
I just came.
Is ipfs usage growing? Stagnant? No idea... Diatributed serving of content seems great
I never really quite understood IPFS and why it gets used where I see it today. What problem is it solving?
TOML instead of YAML or JSON for configuration.
YAML is complex and has security concerns most people are not aware of.
JSON works, but the block quoting and indenting is a lot of noise for a simple category key value format.
TOML is not a very good format IMO. It's fine for very simple config structures, but as soon as you have any level of nesting at all it becomes an unobvious mess. Worse than YAML even.
What is this even?
[[fruits]]
name = "apple"
[fruits.physical]
color = "red"
shape = "round"
[[fruits.varieties]]
name = "red delicious"
[[fruits.varieties]]
name = "granny smith"
[[fruits]]
name = "banana"
[[fruits.varieties]]
name = "plantain"
That's an example from the docs, and I have literally no idea what structure it makes. Compare to the JSON which is far more obvious:
{
"fruits": [
{
"name": "apple",
"physical": {
"color": "red",
"shape": "round"
},
"varieties": [
{ "name": "red delicious" },
{ "name": "granny smith" }
]
},
{
"name": "banana",
"varieties": [
{ "name": "plantain" }
]
}
]
}
The fact that they have to explain the structure by showing you the corresponding JSON says a lot.
JSON5 is much better IMO. Unfortunately it isn't as popular and doesn't have as much ecosystem support.