A picture of bowls of eggs, flour, sugar, water, butter an sugar wit the text:
Happy 34th Birthday, Linux!
Here’s your cake, go ahead and compile it yourself.
Edit: fixed the text in the image to “34th”

Fuck the police waiting straight for the underground
A limp walker got it bad sittin’ down
Chaotic noodle
yum install -y mint-choc # 😋
I’ve had it at the 27th for a few years in my calendar now, but I have no idea why, lol.
Apparently the official birthday should be August 25th, so maybe I mixed those up?
That look delicious, tysm!
A picture of bowls of eggs, flour, sugar, water, butter an sugar wit the text:
Happy 34th Birthday, Linux!
Here’s your cake, go ahead and compile it yourself.
Edit: fixed the text in the image to “34th”
Please don’t reinvent the weel and just install a Turbo Roundabout. It’s much safer for everyone, incuding cars.
Just one more ~~lane~~ layer bro, trust me bro.
AGPL 😎
Edit: this looks pretty slick, I’ll keep it in mind next time I need a cache
“Capitalism creates innovation!”
The innovation:

Well yes, assuming that:
With this you can make your laptop very tamper resistant. It will be basically impossible to tamper with the bootloader while the laptop is off. (e.g install keylogger to get disk-encryption password).
What they can do, is wipe the bios, which will remove your custom keys and will not boot your computer with secure boot enabled.
Something like a supply-side attack is still possible however. (e.g. tricking you into installing a malicious bootloader while the PC is booted)
Always use security in multiple layers, and to think about what you are securing yourself from.
And don’t just fork it on GitHub, if the original repo gets deleted, any forks might too.
Also do a git clone locally, or set up a mirror on another host.

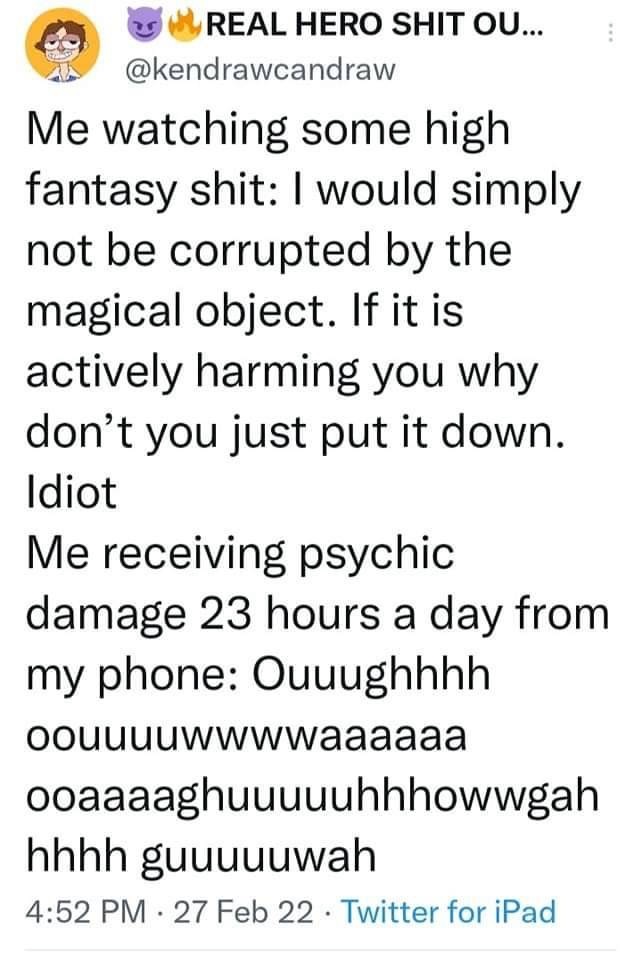
Tweet is from around February 2022; I’m not visiting that cesspool to find the exact date.

GIF of Mr. Bean looking for something in a panicked manner with the caption: “me trying to find the remote until the skip intro button disappears”








Apparently it’s xkcd 3171