See the post on BlueSky: https://bsky.app/profile/provisionalidea.bsky.social/post/3lhujtm2qkc2i
According to many comments, the US government DOES use SQL, and Musk is not understanding much what's going on.
I don't know where you got that image from. AllenAI has many models, and the ones I'm looking at are not using those datasets at all.
Anyway, your comments are quite telling.
First, you pasted an image without alternative text, which it's harmful for accessibility (a topic in which this kind of models can help, BTW, and it's one of the obvious no-brainer uses in which they help society).
Second, you think that you need consent for using works in the public domain. You are presenting the most dystopic view of copyright that I can think of.
Even with copyright in full force, there is fair use. I don't need your consent to feed your comment into a text to speech model, an automated translator, a spam classifier, or one of the many models that exist and that serve a legitimate purpose. The very image that you posted has very likely been fed into a classifier to discard that it's CSAM.
And third, the fact that you think that a simple deep learning model can do so much is, ironically, something that you share with the AI bros that think the shit that OpenAI is cooking will do so much. It won't. The legitimate uses of this stuff, so far, are relevant, but quite less impactful than what you claimed. The "all you need is scale" people are scammers, and deserve all the hate and regulation, but you can't get past those and see that the good stuff exists, and doesn't get the press it deserves.
Which ones? Name one.
What's wrong with what Pleias or AllenAI are doing? Those are using only data on the public domain or suitably licensed, and are not burning tons of watts on the process. They release everything as open source. For real. Public everything. Not the shit that Meta is doing, or the weights-only DeepSeek.
It's incredible seeing this shit over and over, specially in a place like Lemmy, where the people are supposed to be thinking outside the box, and being used to stuff which is less mainstream, like Linux, or, well, the fucking fediverse.
Imagine people saying "yeah, fuck operating systems and software" because their only experience has been Microsoft Windows. Yes, those companies/NGOs are not making the rounds on the news much, but they exist, the same way that Linux existed 20 years ago, and it was our daily driver.
Do I hate OpenAI? Heck, yeah, of course I do. And the other big companies that are doing horrible things with AI. But I don't hate all in AI because I happen to not be an ignorant that sees only the 99% of it.
I've made several Qt apps (in C++) easily packaged using AppImage. Perhaps OBS is harder because they require some level of integration with the hardware (e.g. the virtual camera perhaps requires something WRT drivers, I don't know), but in the general case of a Qt app doing "normal GUI stuff" and "normal user stuff" is a piece of cake. To overcome the glibc problem, it's true that it's recommended using an old distro, but it's not a must. Depends on what you want to support.
As a user, I prefer a native package, though (deb in my case).
My bad, I forgot he doesn't have time to think.
Too busy being one of the best players at Path of Exile 2. Despite that he doesn't identify the valuable loot. Or how to use the map. Or how levels work. But he's top 50! All very believable.
Ah, a classic watch. :-)
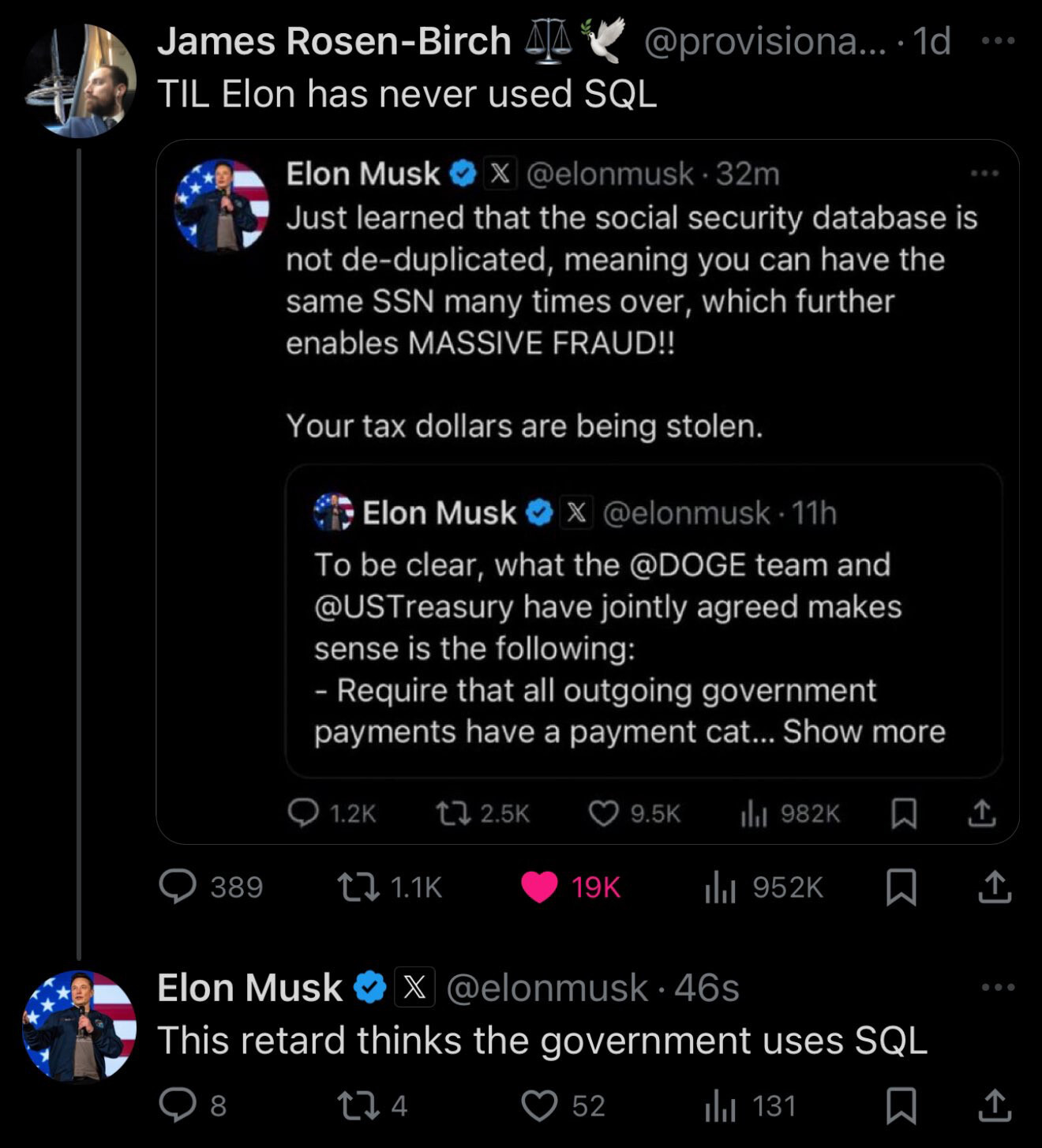
Elon probably thinks that SQL is MS SQL Sever, MySQL, or some such.
See the post on BlueSky: https://bsky.app/profile/provisionalidea.bsky.social/post/3lhujtm2qkc2i
According to many comments, the US government DOES use SQL, and Musk is not understanding much what's going on.
I think that "exactly like" it's absurd. Bubbles are never "exactly" like the previous ones.
I think in this case there is a clear economical value in what they produce (from the POV of capitalism, not humanity's best interests), but the cost is absurdly huge to be economically viable, hence, it is a bubble. But in the dot com bubble, many companies had a very dubious value in the first place.
Lol. We’re as far away from getting to AGI as we were before the whole LLM craze. It’s just glorified statistical text prediction, no matter how much data you throw at it, it will still just guess what’s the next most likely letter/token based on what’s before it, that can’t even get it’s facts straith without bullshitting.
This is correct, and I don't think many serious people disagree with it.
If we ever get it, it won’t be through LLMs.
Well... depends. LLMs alone, no, but the researchers who are working on solving the ARC AGI challenge, are using LLMs as a basis. The one which won this year is open source (all are if are eligible for winning the prize, and they need to run on the private data set), and was based on Mixtral. The "trick" is that they do more than that. All the attempts do extra compute at test time, so they can try to go beyond what their training data allows them to do "fine". The key for generality is trying to learn after you've been trained, to try to solve something that you've not been prepared for.
Even OpenAI's O1 and O3 do that, and so does the one that Google has released recently. They are still using heavily an LLM, but they do more.
I hope someone will finally mathematically prove that it’s impossible with current algorithms, so we can finally be done with this bullshiting.
I'm not sure if it's already proven or provable, but I think this is generally agreed. just deep learning will be able to fit a very complex curve/manifold/etc, but nothing more. It can't go beyond what was trained on. But the approaches for generalizing all seem to do more than that, doing search, or program synthesis, or whatever.
Wow, thanks, I have not seen this comment, yet I hinted about this in some of my other replies that I've done before.
Yes, I think ML is fair use, but there it would also be fair to force something into the public domain/open source if, in order to be accrued, it has to make use of fair use at unseen amounts of scale.
This would be a difficult to make law, though. Current ML is very inefficient in the amount of data it requires, but it could (and should) be made better.
Now I sail the high seas myself, but I don’t think Paramount Studios would buy anyone’s defence they were only pirating their movies so they can learn the general content so they can produce their own knockoff.
We don't know exactly how they source their data (and that is definitely shady), but if I can gain access to a movie in a legal way, I don't see why I would not be able to gather statistics from said movie, including running a speech to text model to caption it, then make statistics of how many times a few words were used, and followed by which ones. This is an oversimplified explanation of what a LLM does, but it's the fairest I can come up, and it would be legal to do so. The models are always orders of magnitude smaller than the data they are trained on.
That said, I don't imply that I'm happy with the state of high tech companies, the AI hype, the energy consumption, or the impact on the humble people. But I've put a lot of thought into this (and learning about machine learning for real), and I think this is not a ML problem, but a problem in the economic, legal and political system. AI hype is just a symptom.
It’s not AI
It's not AGI, it's not general intelligence, and it's not comparable to a human (well, you can compare anything, but human and ML are just very different things in tons of ways).
But it is AI. The ghosts that chase Pacman are AI. A search algorithm is also AI, dammit. Of course an LLM is AI. Any agent that maximizes a function is AI. You are just embarrassing yourself.
But then it does go on to quote materials verbatim, which shows it’s not “just” ‘extracting patterns’.
Is is just extracting patterns. Is making statistical samples of which token ("word", informally speaking) is likely followed given the previous stream.
It can only reproduce passages of things it has seen many, many times. I cannot reproduce the whole work. Those two quotes can be seen elsewhere on the internet plenty of times. And it's fair use there, so it would be fair use with a chat bot as well.
There have been papers published where researchers were able to regenerate an image that was present in the training set of Stable Diffusion. But they were only able to find that image (and others) in particular, because they were present in the training set multiple times, and the caption was the same (it was the portrait picture of some executive at a company).
when given the book and pages — quote copyrighted works
Yeah, you are not gonna be able to do that with an LLM. They will be able to quote only some passages, and only of popular books that have been quoted often enough.
Even if they started to use my service to literally copy entire books?
You cannot do that with an LLM.
Why are you defending massive corporations who could just pay up? Isn’t the whole “corporations putting profits over anything” thing a bit… seen already?
I hate that some corporations are burning money, resources and energy on this, and the solution is not to restrict fair use even further. Machine Learning is complex, but if I had to summarize in some way is "just" gathering statistics of which word comes next (in the case of a text model). This is no different than getting a large corpus of text, and sample it for word frequency, letter frequency, N-gram frequency, etc. It is well known that this is fair use. You only store the copyrighted works to run the software and produce a very transformative work that is a summary many orders of magnitude smaller than the copyrighted work. This is fair use, and it should still be. Changing that is gonna harm the public, small companies and independent researchers way more than big tech companies.
As I said in another comment, I would very much welcome a way to force big corpos to release their models. Make a model bigger than N parameters? You needed too much fair use in one gulp: your model has to be public, and in the public domain. I would fucking welcome that! But going in the opposite direction is just risky.
I don't understand why small individuals think that copyright is their friend, and will protect them from big tech companies. Copyright will always harm the weak and protect the powerful as a net result. It's already a miracle that we can enjoy free software and culture by licenses that leverage copyright in our favor.
Transcription: a Twitter thread from Gary Bernhardt.
Source: https://twitter.com/garybernhardt/status/1344341213575483399

Aaron was facing charges, and a really bad deal, and he took his life. He was never sentenced because there was no time for that, but it's obvious that things weren't going well for him, and that he was attacked disproportionally.
Meta is still facing investigation and will go to court still, and will very likely face charges for torrenting the data, same as Anthropic. They have not been sentenced because there was been no trial yet, it's still under investigation, because it will be a harsher penalty if it can be proved that they uploaded in addition to downloaded.
I think this is inaccurate enough to consider it misinformation (IMHO).
Yes, it is obvious that we all should fight Meta and praise Aaron Swartz. And it's true that the legal system is fucked up, and someone with power and money is in total advantage. But as despicable as Meta is, I don't think that saying wrong things is going to be the way to fight for our rights. There are already good enough arguments if we stay true to the facts.