Oh wow look at that beautiful website that made uBlock shine like a Christmas Tree ! What a beautiful specimen !
N0x0n
joined 1 year ago
Yeah ! Except in the dev/code realm... They seem very aggressive to each other, specially if you whisper something like: Rust is safer than C !
I don't really get it, but I find It very pleasant to read when passionate people write a whole essay I don't even understand 1/10 of what they are writing... However, there seems some heated negativity in that community !
Are people in the US aware that they are now definitely a rogue state, or is this fact covered up by the usual patriotism somehow?
Huh? Never did I mentioned to not participate in society. On the contrary. However I find it a bit hypocrite...
Would France boycott coca cola, McD, Tesla if Trump wasn't elected? ://
France should boycott France?! Let's be realistic, how does someone like Macron is still in power despite the new votes to take him down?
Just my personal opinion, I'm not versed enough in politics to judge anyone. However, I have read a lot about how those multi billion dollar companies destroy our kids future...
Boycott for the real reason, not with a sketchy political background !
Oupsii !

cross-posted from: https://lemmy.ml/post/15968883
Hello everyone ! Nobody seems to have an answer on !networking@sh.itjust.works (or maybe they are not interested because it's an enteprise network community?) and !homenetworking@selfhosted.forum seems dead?
Anyway, If anyone could guide me or direct me to the right direction, I would really appreciate it !
TL:DR
What is encapsulated into the frame that makes everyone understand: "OHHH that’s for 10.0.0.8, your docker container on bridge network br-b1de on the veth2b interface !!! "
Hi everyone !
I'm scratching my head in finding an actual answer on how virtual networking in docker actually works (mostly on the packets/frame level) or some good documentation to improve my understanding on how everything fits together.
Because I'm probably lacking the correct network terminology I made a simple network topology of my network. Don't hesitate to correct any network mistake.
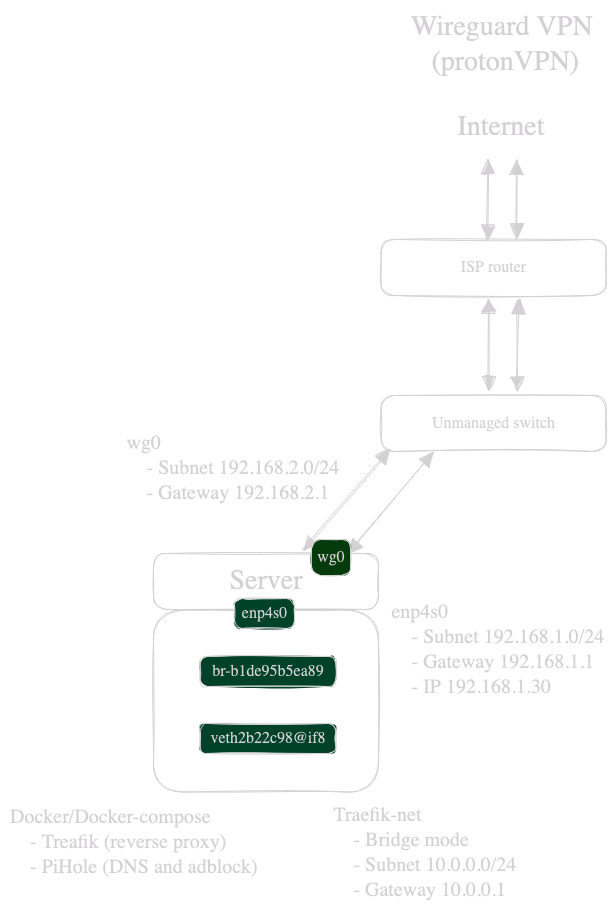
In my scenario, my docker container with the virtual interface veth2b22c98 and the following ip (10.0.0.8) connects to bridge network br-b1de95b5ea89. When I curl, from my conntainer, lemmy.ml the packets/frame is send to my enp4s0 and goes through my wireguard tunnel to my VPN provider which sends back the packet/frame/handshake...
I probed every interface with tcpdump (enp4s0, wg0, br-b1,veth2b):
-
enp4s0: Every packet/frame is encapsulated into the wireguard protocol with my physical interface's IP (192.168.1.30) and no DNS is visible on that interface (like expected) and sends it out to my ISP's public IP.
-
wg0: Shows every packet/frame with the actual protocol with my wireguard's interface IP (192.168.2.1) with the destination IP of lemmy.ml (Dst: 54.36.178.108)
-
br-b1: Shows every packet/frame with the actual protocol with my containers IP (10.0.0.8) with the destination IP of lemmy.ml (Dst: 54.36.178.108)
I know there is a mix of 2 different concepts in my scenario (wireguard tunnel and virtual networking) but I really do not understand how the frame gets back to my docker container. When I look at the frames on wg0, there is no mention of either the MacAddress of my container or the actual IP of my container.
How/when/what ? is exactly happening to my frame so that it gets to the correct target between my physical interface, virtual interface, bridge ? I mean with VLAN's there's a VLAN tag on the frame, so you can easily identify with Wireshark where it should go. But here, I cannot find any clue who or what is doing the magic so the frame finds it's way back to my docker container.
What is encapsulated into the frame that makes everyone understand: "OHHH that's for 10.0.0.8, your docker container on bridge network br-b1de on the veth2b interface !!! "
Sorry for my broken English and lack of networking terminology and thank you for those who beared with me and are willing the give me some hints/proper networking lesson.
Edit: Whoops I just read that networking@sh.itjust.works is for enterprise networks? I hope my small homelab question doesn't break the rules? If so I will redirect my question.
Hi everyone !
I'm scratching my head in finding an actual answer on how virtual networking in docker actually works (mostly on the packets/frame level) or some good documentation to improve my understanding on how everything fits together.
Because I'm probably lacking the correct network terminology I made a simple network topology of my network. Don't hesitate to correct any network mistake.
In my scenario, my docker container with the virtual interface veth2b22c98 and the following ip (10.0.0.8) connects to bridge network br-b1de95b5ea89. When I curl, from my conntainer, lemmy.ml the packets/frame is send to my enp4s0 and goes through my wireguard tunnel to my VPN provider which sends back the packet/frame/handshake...
I probed every interface with tcpdump (enp4s0, wg0, br-b1,veth2b):
-
enp4s0: Every packet/frame is encapsulated into the wireguard protocol with my physical interface's IP (192.168.1.30) and no DNS is visible on that interface (like expected) and sends it out to my ISP's public IP.
-
wg0: Shows every packet/frame with the actual protocol with my wireguard's interface IP (192.168.2.1) with the destination IP of lemmy.ml (Dst: 54.36.178.108)
-
br-b1: Shows every packet/frame with the actual protocol with my containers IP (10.0.0.8) with the destination IP of lemmy.ml (Dst: 54.36.178.108)
I know there is a mix of 2 different concepts in my scenario (wireguard tunnel and virtual networking) but I really do not understand how the frame gets back to my docker container. When I look at the frames on wg0, there is no mention of either the MacAddress of my container or the actual IP of my container.
How/when/what ? is exactly happening to my frame so that it gets to the correct target between my physical interface, virtual interface, bridge ? I mean with VLAN's there's a VLAN tag on the frame, so you can easily identify with Wireshark where it should go. But here, I cannot find any clue who or what is doing the magic so the frame finds it's way back to my docker container.
What is encapsulated into the frame that makes everyone understand: "OHHH that's for 10.0.0.8, your docker container on bridge network br-b1de on the veth2b interface !!! "
Sorry for my broken English and lack of networking terminology and thank you for those who beared with me and are willing the give me some hints/proper networking lesson.
Edit: Changed something on my network diagram (wireguard is not in a container it's bare bone on the server) and some typo.
view more: next ›
It raised even more questions... However, It hints you in "understanding" that we are all connected in this strange global consciousness soup ! We are the universe reflecting itself. Mushrooms can be your buddies or your worst nightmare...
Yep, it raises more question than answering any you had beforehand !