this post was submitted on 24 May 2025
7 points (100.0% liked)
Forum Libre
1007 readers
80 users here now

Communautés principales de l'instance
Nous rejoindre sur Matrix: https://matrix.to/#/#jlai.lu:matrix.org
Une communauté pour discuter de tout et de rien:
- Fil quotidien "comment allez-vous?"
- Contenu détendu
- Questions à la communauté
- Aujourd'hui j'ai appris
- Anecdotes personnelles
- Bonnes nouvelles
- Projets locaux / associatifs
- Inspiration
- BD / illustrations
- Etc.
Les mots d'ordre sont : respect et bienveillance.
Les discussions politiques sont déconseillées, et ont davantage leur place sur
- !france@jlai.lu
- !monde@jlai.lu
- !belgique@jlai.lu
- !luxembourg@lemmy.world
- !quebec@lemmy.ca
- !suisse@lemmy.world
Les règles de l'instance sont bien entendu d'application.
Fils hebdomadaires"
- Lundi Méta
- Mardi Créatif
- Mercredi CinéSéries
- Jeudi Tech
- Vendredi Livres
- Samedi DJ/Musique
- Dimanche Jeux Videos
"Demandez-moi n'importe quoi"
- Je suis un maraicher en bio sur petite surface - DMN (AMA)
- Je serai bientôt ordonné pasteur protestant, demandez-moi ce que vous voulez !
- Je bosse au 4/5 sur les modèles de langage (LLM, parfois appelées IAs) et à 2/5 sur la robotique open hardware AMA
Communautés détendues
Communautés liées:
Loisirs:
- !cineseries@jlai.lu
- !cyclisme@sh.itjust.works
- !jeuxvideo@jlai.lu
- !jardin@lemmy.world
- !jeuxvideo@jlai.lu
- !livres@jlai.lu
- !motardie@jlai.lu
- !sport@jlai.lu
- !technologie@jlai.lu
Vie Pratique:
Communautés d'actualité
Société:
Pays:
- !monde@jlai.lu
- !belgique@jlai.lu
- !france@jlai.lu
- !luxembourg@lemmy.world
- !quebec@lemmy.ca
- !suisse@lemmy.world
Communauté de secours:
founded 2 years ago
MODERATORS
you are viewing a single comment's thread
view the rest of the comments
view the rest of the comments
J'ai demandé à chatgpt via duck.ai de me rappeler la formule wget pour télécharger tous les documents pdf proposés sur une page internet.
Il m'a proposé ça :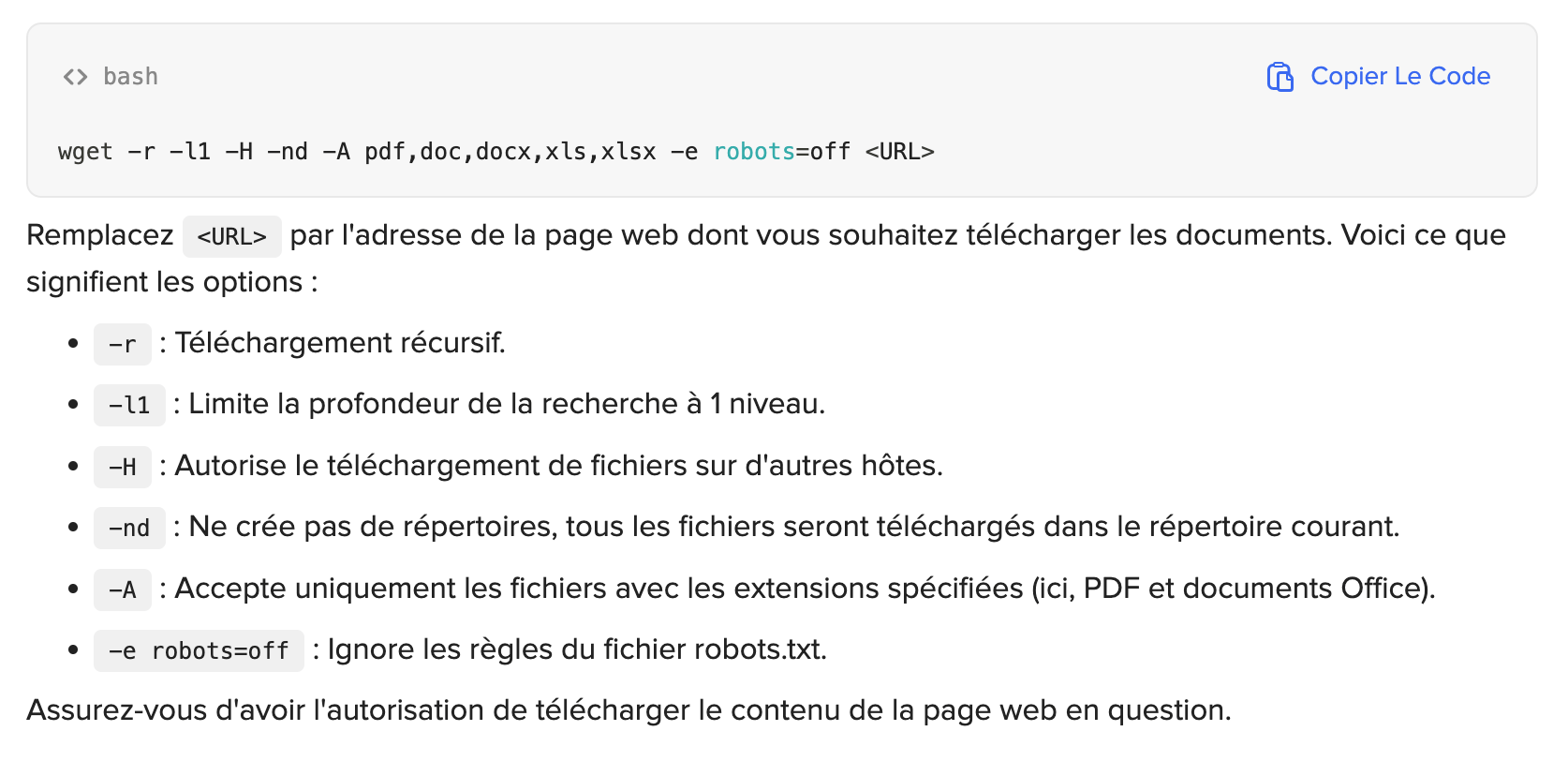
C'est normal la commande pour ignorer robots.txt ?
Ps : je trouve ça dingue déjà
Je ne m’y connais pas du tout, mais n’est-ce pas contradictoire avec le fait d’ignorer robots.txt ?
Pareil que toi, mais ça me semble bien contradictoire. Si je dis pas de bêtises, le document robots.txt est un document non contraignant, c'est plutôt une convention.
https://robots-txt.com/
Ah voilà, j'ai retrouvé le post d'@innermeerkat@jlai.lu (coucou!) à ce sujet : https://jlai.lu/post/16807807
Coucou !