I recently integrated self-hosted Ollama with Home Assistant and it's pretty cool.
I'd like to also be able to ask the Home Assistant Assist things like "What movies are playing in MyCity?" and have the model in Ollama search the web and summarize the results. I use Open-WebUI as a frontend for Ollama and it can do that, but I can't see how configure HA's Assist to do it.
Has anyone done this?
Another example would be to ask "what's the weather today?", and I realize that HA has a weather integration built in and thus I wouldn't need Ollama to search the web for results. Is there a web search integration for HA, so that any question (like "what movies are playing") could be passed to it?
My ultimate goal is to be able to ask questions about the world (i.e., search the web and summarize the results) and control Home Assistant devices. It doesn't have to be HA's Assist, but if I were to use Open-WebUI* for example, I'd have to come up with a way to link my audio-listening devices to it. It also doesn't have to be one "entity", but it should "feel like" one entity to the user (i.e., I don't want to have to speak to a different device or have a different wakeword to ask about the world than I do to control Home Assistant).
*Open-WebUI has integrations to control Home Assistant.

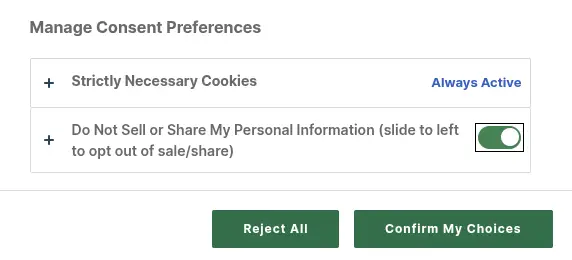 The option is called "Do Not Sell or Share My Personal Information", which suggests that by selecting the option, you want them to not sell or share your information. But in parentheses it adds "slide left to opt out of sale/share", which suggests that disabling the option means for them to not sell or share your information.
The option is called "Do Not Sell or Share My Personal Information", which suggests that by selecting the option, you want them to not sell or share your information. But in parentheses it adds "slide left to opt out of sale/share", which suggests that disabling the option means for them to not sell or share your information.

I haven't had to adjust or look at my invidious instance configs in a long time, but I do remember that in their docker instructions and I think I configured my container to restart hourly (or maybe I made it every other hour? Daily?). I've had no problems with my invidious instance in a long time, but that may have nothing to do with frequent restarts.