Boba egg chain/cluster
Sagu is even more similar, since it's smaller:

Boba egg chain/cluster
Sagu is even more similar, since it's smaller:
Bad connection, eh? Either Starlink is crap and prone to bad connections... or not even its owner uses it.
100% yes. A few things I've learned with conlanging:
It's fun to see how closer and closer to language it's getting - compositionality is a big deal for human language.
Think in English a bit. Would you sleep a car? Not really, right? The verb is intransitive, you don't need a direct object. And if you really want to use one, you'd say what you slept - a nap, a beauty sleep, etc.
German "schlafen" is the same deal, it requires no direct object. And if you were to force one, you'd end with something like "ich schlafe meinen Schönheitsschlaf" (I sleep my beauty sleep) - note how the accusative is there.
So the role of that "in meinem Auto" (in my car) is something else: it's an optional complement telling you where that action happens. German typically handles this through prepositional phrases (Präpositionalphrase), so the preposition dictates which case you need to use:
When the preposition allows either, typically you use the accusative when the subject is changing locations. For example:
I feel like those tech companies will do this "let's set up a façade in Vietnam, until Vietnam gets tariffed and we do it elsewhere" silly dance for now. But eventually they'll stop caring - as USA's customer market becomes increasingly impoverished, it becomes less of an issue to appease its whimsy kinglet.
Sure! Basic syllable is (C)(r,u,i)V(r,u,i,n,f,s,h), with the following additional restrictions:
For reference, here's the full set of phonemes, with romanisation (the default was Cyrillic):
| Phonemes | Cyr. | Lat. | notes |
|---|---|---|---|
| /p t k b d g/ | ⟨п т к б д г⟩ | ⟨p t k b d g⟩ | /p t k/ can be aspirated |
| /ɸ s x/ | ⟨ф с х ⟩ | ⟨f s h⟩ | /f/ = [ɸ~f], /s/ = [s~ʃ], /x/ = [x~h] |
| /m n/ | ⟨м н⟩ | ⟨m n⟩ | coda /n/ can be any nasal in coda, even [m] |
| /ts r/ | ⟨ц р⟩ | ⟨z r⟩ | /ts/ = [ts~tʃ], /r/ = [r ɾ l] |
| /i u/ | ⟨и/й у/ў⟩ | ⟨i/j u/w⟩ | the second spelling for each vowel is only when bordering another vowel |
| /ä e o/ | ⟨а е о⟩ | ⟨a e o⟩ | /e/ = [ɛ~e], /o/ = [ɔ~o], /ä/ = any low vowel |
I did something like this years ago. My phonology was surprisingly close to yours, as I used PHOIBLE's list of the most common sound segments as a basis. Main difference was phonotactics, since I allowed more complex onsets.
I'd suggest you to get rid of the rhotic, and instead allow /l/ to surface as [l ɾ r ɹ]. Three reasons:
Loanwords will become rather opaque, and yet you'll probably want a few of them for content words, as they're often quick to identify even if you don't speak the language. This can be alleviated if you have specific rules to adapt loanwords into your conlang - for example, where to insert epenthetic vowels, which vowel it should be (echo vowel? /e/? etc.).
I'm a muppet. Thanks for pointing it out - fixed.
Yes. But only distantly though.
The Latin name Austria is literally "southernia". It's a mistranslation of Old High German Ōstarrīhhi "eastern realm"; auster/ōstar sound similar because they are cognates indeed, but they mean different directions. A more accurate Latinisation would be probably Orientia; from oriens "east".
In the meantime Australia was the result of some XVII century Latin, ⟨terra australis incognita⟩ "unknown southern land".
Probably not.
If some breakthrough appears, I expect it to be a bilingual inscription containing the same text in Linear A and Linear B; similar to the Rosetta stone for Egyptian, having the text also in Greek was key.
This infographic is still incomplete; I'm posting it here in the hope that I can get some feedback about it. It has three goals:
Criticism is welcome as long as constructive.
EDIT: OK, too much text. I'm clipping as much as I can.

This is not some sort of fancy new development, but it's such a classical experiment that it's always worth sharing IMO. Plus it's fun.
When you initially mix both solutions, nothing seems to happen. But once you wait a wee bit, the colour suddenly changes, from transparent to a dark blue.
There are a bunch of variations of this reaction, but they all boil down to the same things:
"Wait a minute, why are there a reducing agent and an oxidiser, doing opposite things? They should cancel each other out!" - well, yes! However this does not happen instantaneously. And eventually the reducing agent will run dry (as long as there's enough oxidiser), the triiodide will pile up, react with the starch and you'll get the blue colour.
Here are simplified versions of the main reactions:
(C₆H₆O₆ = dehydroascorbic acid) Eventually #2 stops happening because all vitamin C was consumed, so the triiodide piles up, reacts with the starch, and suddenly blue:

EDIT: @[email protected] shared something that might help to circumvent this shit:
Contained in these parentheses is a zero-width joiner: ()
Basically, add those to whatever you feel that might be filtered out, then remove the parentheses. The content inside the parentheses is invisible, but it screws with regex rules.
Based on
SVG source for anyone willing to give it a try. Made with Inkscape. The emojis were added as images because Inkscape.

Aue, patrue placentae! (Oi, tio do pavê!)
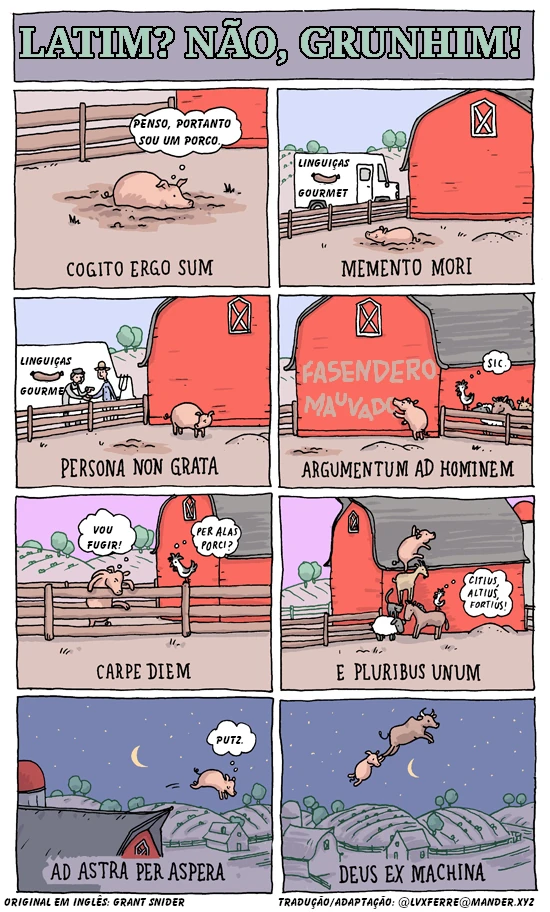


{kind=link}
And one of the muppets behind Reddit, kn0thing.