This whole thing is just a nice reminder to not go overboard and use a 3rd party library when it's completely unnecessary. I never had a need to use sth like fluent validations when you can do pretty much the same thing by writing the validation method directly in your Dto, it's a bit verbose but at least it also lets you have more control over the whole thing. Maybe I just never used it on a scale enough to justify the library but it seems completely superfluous, dunno
Cyno
joined 2 years ago
I only used obsidian for a few weeks so i didnt get that used to it, but what you mean could be the mental switch from hierarchical file structure in obsidian to logseq's journaling/time based one? You're supposed to organize data with tags rather than remembering their location and structure in folders. I spend most time searching for tags, not specific files, and in that way it's functional enough for me, although I do not really understand the query syntax yet so I am unable to create more complex searches in this way. Tbh I'm hoping the sqllite switch lets me just write direct SQL
For a specific example, instead of having folders like Software > Programming > csharp > my projects > projectx ... I will just have a page for the project that has tags #programming #csharp #myprojects etc. And then I can search for #myproject and see all relevant info for it, even sorted by the date when i added it which adds some nice historical context
I switched to Logseq from Obsidian since I preferred FOSS and it's been a good experience so far. They are working on a big update to switch to an sqlite db for storage which should help with performance (and I hope improve the search experience) so that's exciting too.
It's no reddit in terms of quantity but honesty I've had higher quality topics and discussions here than there. Lemmy/kbin might not have taken off in the mainstream to offer a variety of subjects but when it comes to tech and software I think it's covered well enough and people are generally nicer about it. The main problem is lack of (remotely) good seach function, I dont think the threads are getting indexed by google and the on-site search is atrocious.
I don't know of any discord programming communities, I wish forums were still a thing but the only live one I know of is the jellyfin one after they moved from reddit. Other than that it's here or the various subreddits
I'm hooked all over again, can't wait to get to new content
Thanks for the suggestion! I'm struggling a bit to incorporate that command into podman compose though, I'm reading through this issue and I'm a bit lost.
Do I just add this to sonarr section in my yaml? I tried it and it doesn't seem to have done much
x-podman:
keep-id:uid=1000
Should I try and switch everything to podman kube play as some user there recommended maybe?
i'm using wayland, seems to have been the default
From what I read on their homepage, RPM Fusion just provides non-free software that Fedora/RH don't usually want to ship themselves, it's just precompiled RPMs for all available Fedora versions. Sounds to me like it should be the same, my currently installed nvidia driver version is 555.58.02 but I have no idea if that correlates to the version of 'nvidia software' app. Ugh every issue is just a pandora box of 10 other problems jumping out and strangling you
edit: Seems to have something to do with wayland/xorg? https://old.reddit.com/r/Fedora/comments/zxvrxk/nvidia_x_server_settings/ I have no idea what are the implications of this though
First of all, thanks for the suggestion! I am a bit confused though because my NVIDIA settings doesn't have nearly as many options as that one:
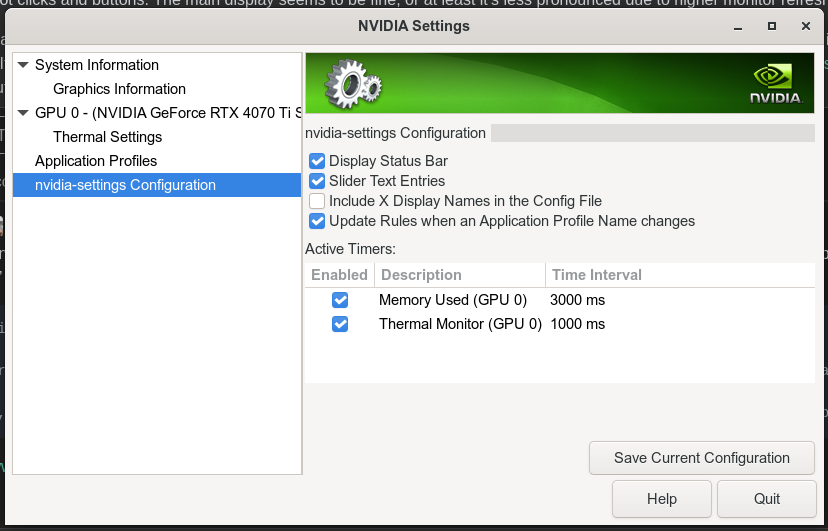
Do I have something incorrectly installed? I followed the instructions from the linked resource to install the rpm fusion nvidia drivers since they aren't available on fedora 40 on the store even with the 3rd party repositories enabled
Doesn't that imply you still have to open up your phone to temporarily share to your pc whenever you need it?
Is this something like the overseerr but for phones?
Ohh I mixed it up with FluentValidations, you are right. I never liked unit tests depending on libraries like that either tbf, vanilla xunit aint that bad either