politics
Welcome to the discussion of US Politics!
Rules:
- Post only links to articles, Title must fairly describe link contents. If your title differs from the site’s, it should only be to add context or be more descriptive. Do not post entire articles in the body or in the comments.
Links must be to the original source, not an aggregator like Google Amp, MSN, or Yahoo.
Example:
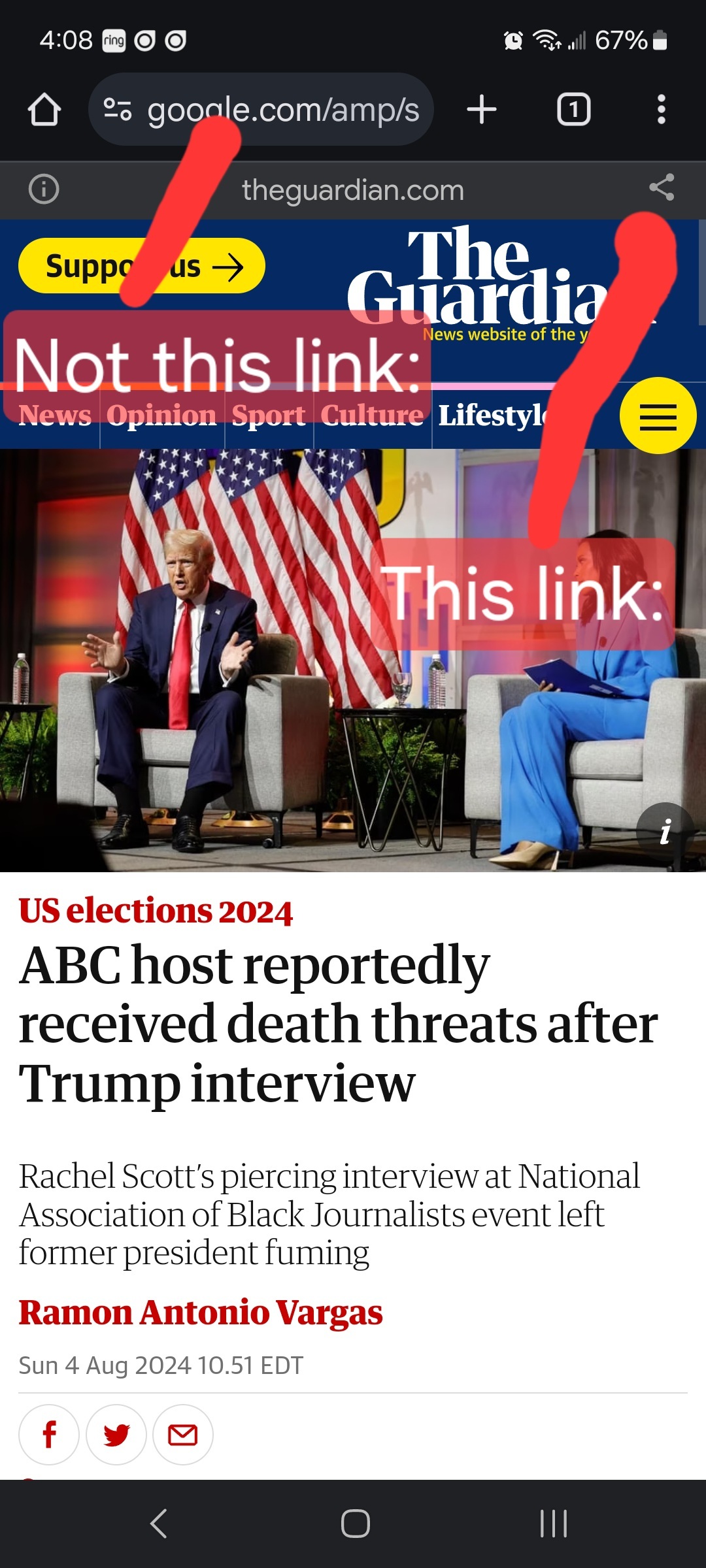
- Articles must be relevant to politics. Links must be to quality and original content. Articles should be worth reading. Clickbait, stub articles, and rehosted or stolen content are not allowed. Check your source for Reliability and Bias here.
- Be civil, No violations of TOS. It’s OK to say the subject of an article is behaving like a (pejorative, pejorative). It’s NOT OK to say another USER is (pejorative). Strong language is fine, just not directed at other members. Engage in good-faith and with respect! This includes accusing another user of being a bot or paid actor. Trolling is uncivil and is grounds for removal and/or a community ban.
- No memes, trolling, or low-effort comments. Reposts, misinformation, off-topic, trolling, or offensive. Similarly, if you see posts along these lines, do not engage. Report them, block them, and live a happier life than they do. We see too many slapfights that boil down to "Mom! He's bugging me!" and "I'm not touching you!" Going forward, slapfights will result in removed comments and temp bans to cool off.
- Vote based on comment quality, not agreement. This community aims to foster discussion; please reward people for putting effort into articulating their viewpoint, even if you disagree with it.
- No hate speech, slurs, celebrating death, advocating violence, or abusive language. This will result in a ban. Usernames containing racist, or inappropriate slurs will be banned without warning
We ask that the users report any comment or post that violate the rules, to use critical thinking when reading, posting or commenting. Users that post off-topic spam, advocate violence, have multiple comments or posts removed, weaponize reports or violate the code of conduct will be banned.
All posts and comments will be reviewed on a case-by-case basis. This means that some content that violates the rules may be allowed, while other content that does not violate the rules may be removed. The moderators retain the right to remove any content and ban users.
That's all the rules!
Civic Links
• Congressional Awards Program
• Library of Congress Legislative Resources
• U.S. House of Representatives
Partnered Communities:
• News
view the rest of the comments
A spellchecker doesn't hallucinate new words. LLMs are not the tool for this job, at best it might be able to take some doctor write up and encode it into a different format, ie here's the list of drugs and dosages mentioned. But if you ask it whether those drugs have adverse reactions, or any other question that has a known or fixed process for answering, then you will be better served writing code to reflect that process. LLMs are best for when you don't care about accuracy and there is no known process that could be codified. Once you actually understand the problem you are asking it to help with, you can achieve better accuracy and efficiency by codifying the solution.
This is why I don't think it should be a critical component or a crutch, or worse, a stand-in for real human expertise, but only acting as another pair of eyes. Certainly grammar checkers and spelling checkers get things wrong, depending on the context.
I use LLMs nearly every day on my job when programming, and holy shit, do they go wildly wrong so many times. Making up entire libraries/projects, etc..
Frankly, I find it a bit terrifying to have these somewhere in the medical pipeline, if left unchecked by real human experts. As others have pointed out, humans often can and do make terrible mistakes. In some critical industries, things like checklists and having at least two people looking at things every step of the way does a lot to eliminate these kinds of (human-caused) problems. I don't know how much the healthcare field uses this kind of idea. I would want LLM to be additive here, not substituting, and acting as a third set of eyes, where the first two (or N, where N > 2) are human, but we know how capitalism works - rather than working to improve outcomes, they want to just lower costs, so I could see LLMs being used as a substitute for what would have been a second pair of human eyes, and I loathe that idea.
But doctors and nurses' minds effectively hallucinate just the same and are prone to even the most trivial of brain farts like fumbling basic math or language slip-ups. We can't underestimate the capacity to have the strengths of a supercomputer at least acting as a double-checker on charting, can we?
Accuracy of LLMs is largely dependent upon the learning material used, along with the rules-based (declarative language) pipeline implemented. Little different than the quality of an education that a human mind receives if they go to Trump University versus John Hopkins.
The difference is that the practitioner can distinguish the difference from hallucination from fact while an LLM cannot.
A supercomputer is only as powerful as it's programming. This is avoiding the whole "if you understand the problem then you are better off writing a program than using an LLM" by hand waving in the word "supercomputer". The whole "train it better" doesn't get away from this fact either.
Sorry, what do you mean by this? Can you elaborate? Hundreds of thousands of medical errors occur annually from exhausted medical workers doing something in error and ultimately "hallucinating," and not having caught themselves. Might, like a spellchecker, an AI have tapped them on the proverbial shoulder to alert them of such an error?
As a software engineer, I understand that; but the capacity to aggregate large amounts of data and to provide a probabilistic determination on risk-assessment simply isn't something a single, exhausted physician's mind can do in a moment's notice no differently than calculating Pi to a million digits in a second. I'm not even opposed to more specialized LLMs being deployed as a check to this, of course.
Example: I know most logical fallacies pretty well, and I'm fairly well versed on current-events, US history, civics, politics, etc. But from time-to-time, I have an LLM analyze conversations with, say, Trump supporters to double-check not only their writing, but my own. It has pointed out fallacies in my own writing that I myself missed; it has noted deviations in facts and provided sources that upon closer analysis, I agreed with. Such a demonstration of auditing suggests it can equally be quite rapidly applied to healthcare in a similar manner, with some additional training material perhaps, but under the same principle.
Since you are a software engineer you must know the difference between deterministic software like a spellchecker and something stochastic like an LLM. You must also understand the difference between a well defined process like a spellchecker and an undefined behavior like an LLM hallucinating. Now ask your LLM if comparing these two technologies in the way you are is a bad analogy. If the LLM says it is a good analogy then you are prompting it wrong. The fact that we can't agree on what an LLM should say on this matter and that we can get it to say either outcome demonstrates that an LLM cannot distinguish fact from fiction, rather it makes these determinations on what is effectively a vibe check.
How about instead you provide your prompt and its response. Then you and I shall have discussion on whether or not that prompt was biased and you were hallucinating when writing it, or indeed the LLM was at fault — shall we?
At the end of day, you still have not elucidated why — especially within the purview of my demonstration of its usage in conversation elsewhere and its success in a similar implementation — it cannot simply be used as double-checker of sorts, since ultimately, the human doctor would go, "well now, this is just absurd" since after all, they are the expert to begin with — you following?
So, naturally, if it's a second set of LLM eyes to double-check one's work, either the doctor will go, "Oh wow, yes, I definitely blundered when I ordered that and was confusing charting with another patient" or "Oh wow, the AI is completely off here and I will NOT take its advice to alter my charting!"
Somewhat ironically, I gather the impression one has a particular prejudice against these emergent GPTs and that is in fact biasing your perception of their potential.
EDIT: Ah, just noticed my tag for you. Say no more. Have a nice day.