Hello everyone!
We have officially hit 1,000 subscribers! How exciting!! Thank you for being a member of !fosai@lemmy.world. Whether you're a casual passerby, a hobby technologist, or an up-and-coming AI developer - I sincerely appreciate your interest and support in a future that is free and open for all.
It can be hard to keep up with the rapid developments in AI, so I have decided to pin this at the top of our community to be a frequently updated LLM-specific resource hub and model index for all of your adventures in FOSAI.
The ultimate goal of this guide is to become a gateway resource for anyone looking to get into free open-source AI (particularly text-based large language models). I will be doing a similar guide for image-based diffusion models soon!
In the meantime, I hope you find what you're looking for! Let me know in the comments if there is something I missed so that I can add it to the guide for everyone else to see.
Getting Started With Free Open-Source AI
Have no idea where to begin with AI / LLMs? Try starting with our Lemmy Crash Course for Free Open-Source AI.
When you're ready to explore more resources see our FOSAI Nexus - a hub for all of the major FOSS & FOSAI on the cutting/bleeding edges of technology.
If you're looking to jump right in, I recommend downloading oobabooga's text-generation-webui and installing one of the LLMs from TheBloke below.
When you're ready, give https://fosai.xyz a visit and check out some of the resources I've placed on there for the community.
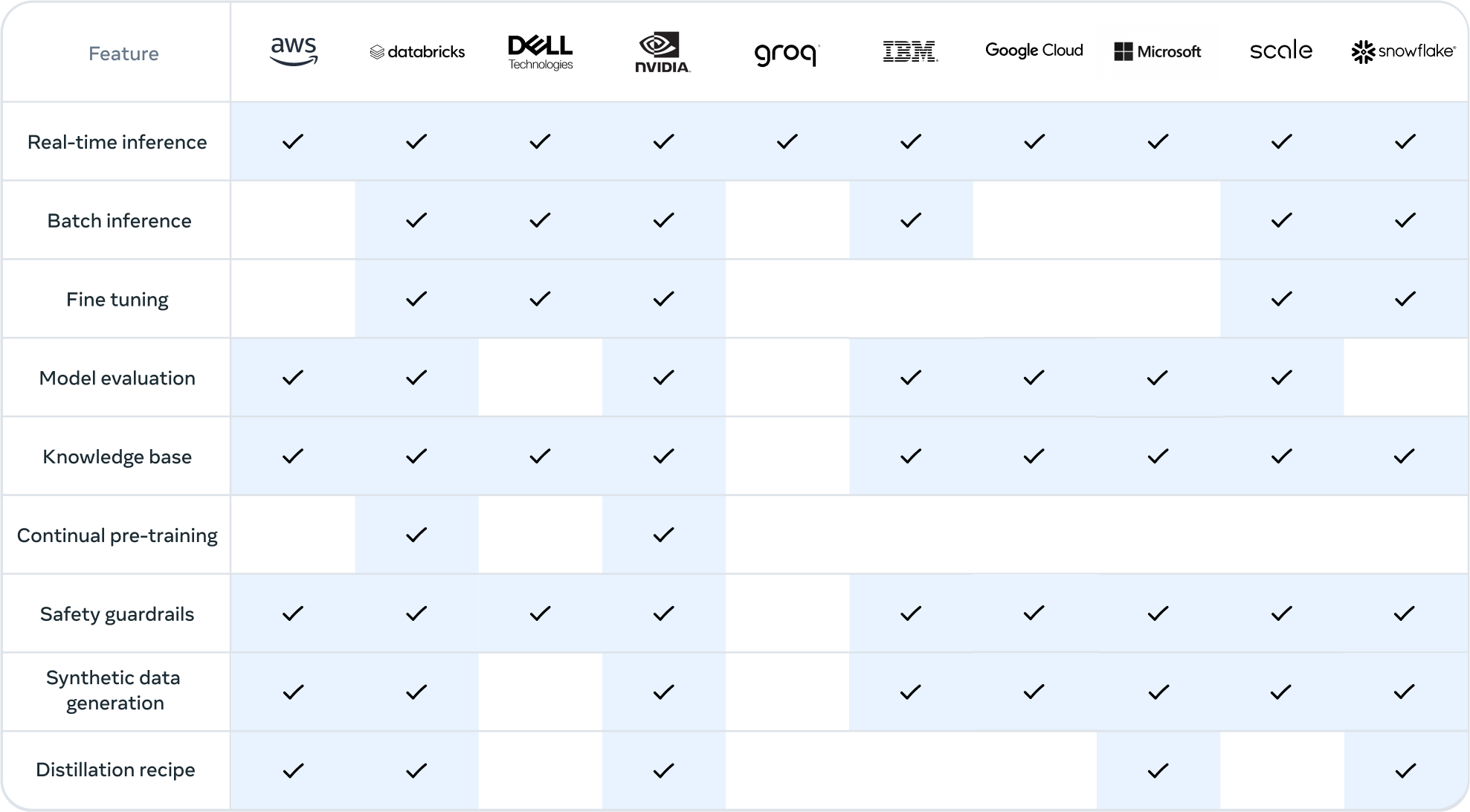
Try both GGML and GPTQ variants to see which model type performs to your preference. See the hardware table to get a better idea on which parameter size you might be able to run (3B, 7B, 13B, 30B, 70B).
8-bit System Requirements
| Model |
VRAM Used |
Minimum Total VRAM |
Card Examples |
RAM/Swap to Load* |
| LLaMA-7B |
9.2GB |
10GB |
3060 12GB, 3080 10GB |
24 GB |
| LLaMA-13B |
16.3GB |
20GB |
3090, 3090 Ti, 4090 |
32 GB |
| LLaMA-30B |
36GB |
40GB |
A6000 48GB, A100 40GB |
64 GB |
| LLaMA-65B |
74GB |
80GB |
A100 80GB |
128 GB |
4-bit System Requirements
| Model |
Minimum Total VRAM |
Card Examples |
RAM/Swap to Load* |
| LLaMA-7B |
6GB |
GTX 1660, 2060, AMD 5700 XT, RTX 3050, 3060 |
6 GB |
| LLaMA-13B |
10GB |
AMD 6900 XT, RTX 2060 12GB, 3060 12GB, 3080, A2000 |
12 GB |
| LLaMA-30B |
20GB |
RTX 3080 20GB, A4500, A5000, 3090, 4090, 6000, Tesla V100 |
32 GB |
| LLaMA-65B |
40GB |
A100 40GB, 2x3090, 2x4090, A40, RTX A6000, 8000 |
64 GB |
*System RAM (not VRAM), is utilized to initially load a model. You can use swap space if you do not have enough RAM to support your LLM.
When in doubt, try starting with 3B or 7B models and work your way up to 13B+.
FOSAI Resources
Fediverse / FOSAI
LLM Leaderboards
LLM Search Tools
Large Language Model Hub
Download Models
text-generation-webui - a big community favorite gradio web UI by oobabooga designed for running almost any free open-source and large language models downloaded off of HuggingFace which can be (but not limited to) models like LLaMA, llama.cpp, GPT-J, Pythia, OPT, and many others. Its goal is to become the AUTOMATIC1111/stable-diffusion-webui of text generation. It is highly compatible with many formats.
A standalone Python/C++/CUDA implementation of Llama for use with 4-bit GPTQ weights, designed to be fast and memory-efficient on modern GPUs.
Open-source assistant-style large language models that run locally on your CPU. GPT4All is an ecosystem to train and deploy powerful and customized large language models that run locally on consumer-grade processors.
The original branch of software SillyTavern was forked from. This chat interface offers very similar functionalities but has less cross-client compatibilities with other chat and API interfaces (compared to SillyTavern).
Developer-friendly, Multi-API (KoboldAI/CPP, Horde, NovelAI, Ooba, OpenAI+proxies, Poe, WindowAI(Claude!)), Horde SD, System TTS, WorldInfo (lorebooks), customizable UI, auto-translate, and more prompt options than you'd ever want or need. Optional Extras server for more SD/TTS options + ChromaDB/Summarize. Based on a fork of TavernAI 1.2.8
A self contained distributable from Concedo that exposes llama.cpp function bindings, allowing it to be used via a simulated Kobold API endpoint. What does it mean? You get llama.cpp with a fancy UI, persistent stories, editing tools, save formats, memory, world info, author's note, characters, scenarios and everything Kobold and Kobold Lite have to offer. In a tiny package around 20 MB in size, excluding model weights.
This is a browser-based front-end for AI-assisted writing with multiple local & remote AI models. It offers the standard array of tools, including Memory, Author's Note, World Info, Save & Load, adjustable AI settings, formatting options, and the ability to import existing AI Dungeon adventures. You can also turn on Adventure mode and play the game like AI Dungeon Unleashed.
h2oGPT is a large language model (LLM) fine-tuning framework and chatbot UI with document(s) question-answer capabilities. Documents help to ground LLMs against hallucinations by providing them context relevant to the instruction. h2oGPT is fully permissive Apache V2 open-source project for 100% private and secure use of LLMs and document embeddings for document question-answer.
Models
The Bloke
The Bloke is a developer who frequently releases quantized (GPTQ) and optimized (GGML) open-source, user-friendly versions of AI Large Language Models (LLMs).
These conversions of popular models can be configured and installed on personal (or professional) hardware, bringing bleeding-edge AI to the comfort of your home.
Support TheBloke here.
70B
30B
13B
7B
More Models
More General AI/LLM Resources
Awesome-LLM: https://github.com/Hannibal046/Awesome-LLM
Awesome Jailbreaks: https://github.com/0xk1h0/ChatGPT_DAN
Awesome Prompts: https://github.com/f/awesome-chatgpt-prompts
Prompt-Engineering-Guide: https://github.com/dair-ai/Prompt-Engineering-Guide
AI Explained (Great channel for AI news): https://piped.video/channel/UCNJ1Ymd5yFuUPtn21xtRbbw
Lex Fridman (In depth podcasts): https://piped.video/channel/UCSHZKyawb77ixDdsGog4iWA
LLM Leaderboards
LLM Logic Tests:
https://docs.google.com/spreadsheets/d/1NgHDxbVWJFolq8bLvLkuPWKC7i_R6I6W/edit#gid=2011456595
llm-leaderboard: https://github.com/LudwigStumpp/llm-leaderboard
Chat leaderboard: https://chat.lmsys.org/?leaderboard
Gotzmann LLM Score v2.4: https://docs.google.com/spreadsheets/d/1ikqqIaptv2P4_15Ytzro46YysCldKY7Ub2wcX5H1jCQ/edit#gid=0
LLM Worksheet: https://docs.google.com/spreadsheets/d/1kT4or6b0Fedd-W_jMwYpb63e1ZR3aePczz3zlbJW-Y4/edit#gid=0
CanAiCode Leaderboard: https://huggingface.co/spaces/mike-ravkine/can-ai-code-results
AlpacaEval Leaderboard https://tatsu-lab.github.io/alpaca_eval/
Measuring Massive Multitask Language Understanding: https://github.com/hendrycks/test
Awesome-LLM-Benchmark: https://github.com/SihyeongPark/Awesome-LLM-Benchmark
Places to Find Models
Discovery the LLMs: https://llm.extractum.io/
Open LLM Models List: https://github.com/underlines/awesome-marketing-datascience/blob/master/llm-model-list.md
OSS_LLMs: https://docs.google.com/spreadsheets/d/1PtrPwDV8Wcdhzh-N_Siaofc2R6TImebnFvv0GuCCzdo/edit#gid=0
OpenLLaMA: An Open Reproduction of LLaMA: https://github.com/openlm-research/open_llama
open-llms: https://github.com/eugeneyan/open-llms
Training & Datasets
Uncensored Models: https://erichartford.com/uncensored-models
LLMsPracticalGuide: https://github.com/Mooler0410/LLMsPracticalGuide
awesome-chatgpt-dataset: https://github.com/voidful/awesome-chatgpt-dataset
awesome-instruction-dataset: https://github.com/yaodongC/awesome-instruction-dataset
GL, HF!
Are you an LLM Developer? Looking for a shoutout or project showcase? Send me a message and I'd be more than happy to share your work and support links with the community.
If you haven't already, consider subscribing to the free open-source AI community at !fosai@lemmy.world where I will do my best to make sure you have access to free open-source artificial intelligence on the bleeding edge.
Thank you for reading!
Update #1
[7/29/23]: I have officially converted this resource into a website! Bookmark and visit https://www.fosai.xyz/ for more insights and information!
Update #2!
[9/22/23]: This guide may be outdated! All GGML model file formats have been deprecated in place of llama.cpp's new GGUF - the new and improved successor to the now legacy GGML format. Visit TheBloke on HuggingFace to find all kinds of new GGUF models to choose from. Use interfaces like oobabooga or llama.cpp to run GGUF models locally. Keep your eye out for more platforms to adopt the new GGUF format as it gathers traction and popularity. Looking for something new? Check out LM Studio, a new tool for researching and developing open-source large language models. I have also updated our sidebar - double check for anything new there or at FOSAI▲XYZ!.
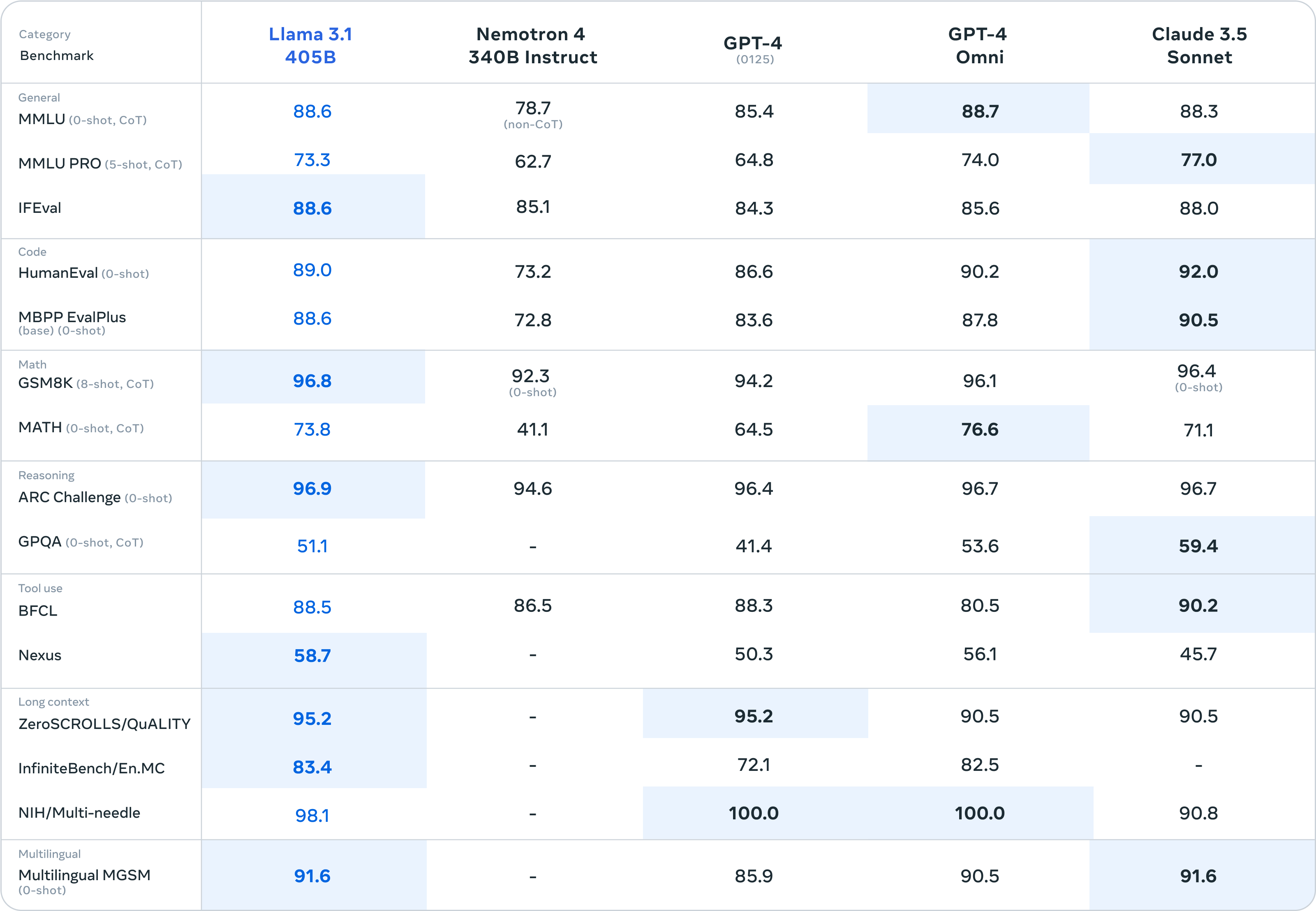
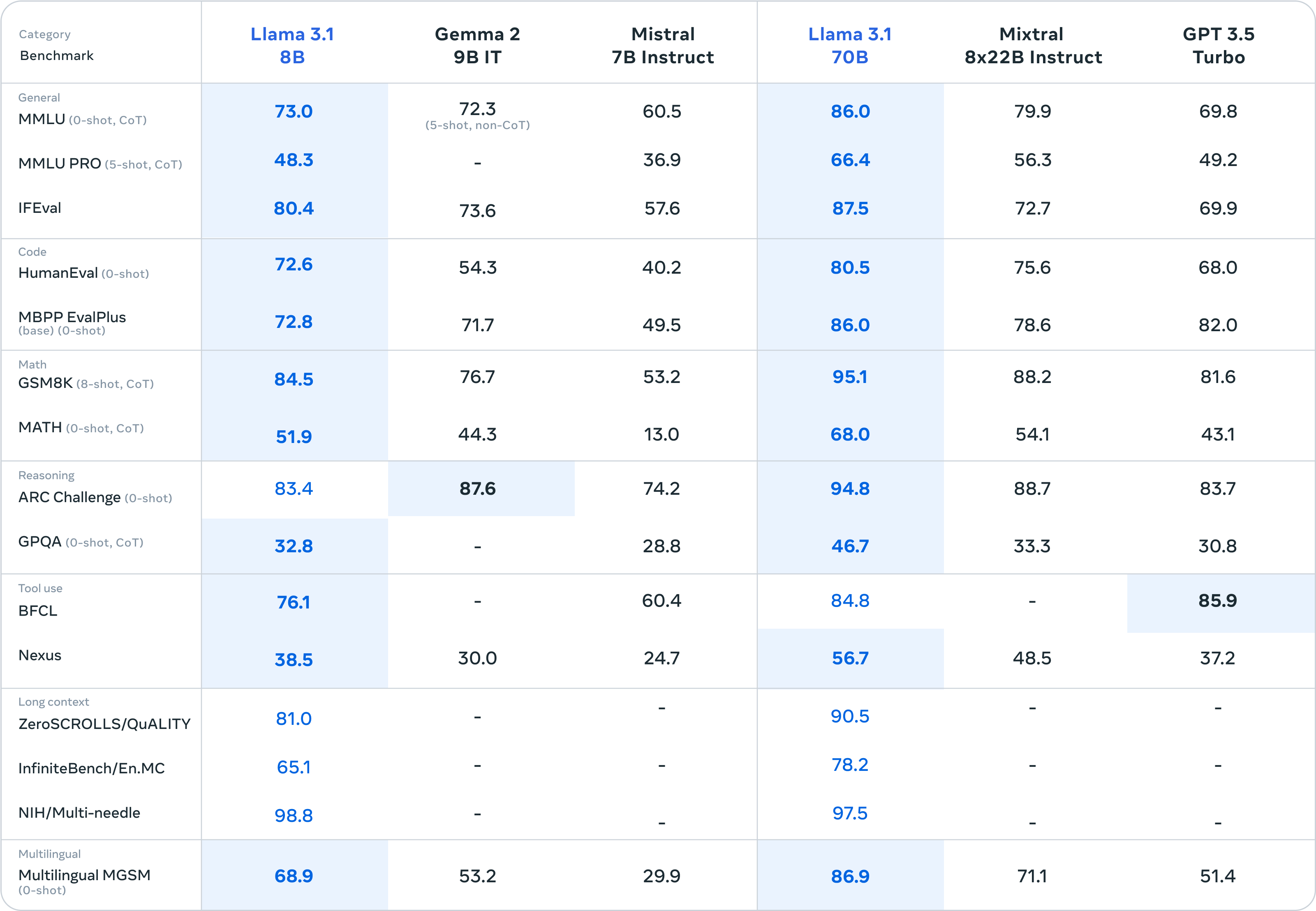
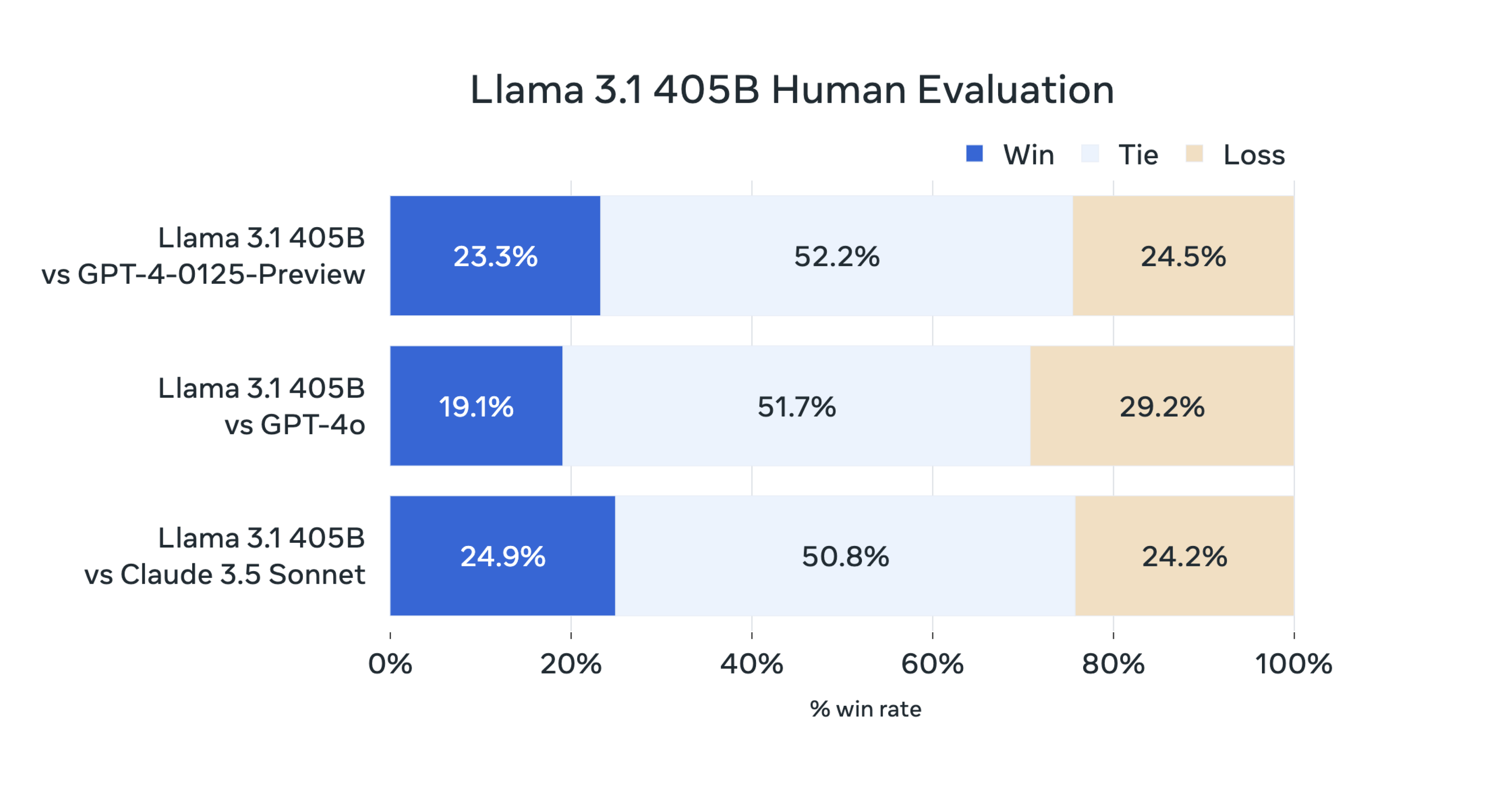


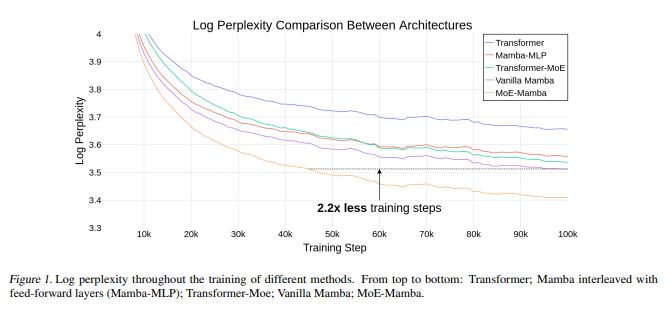
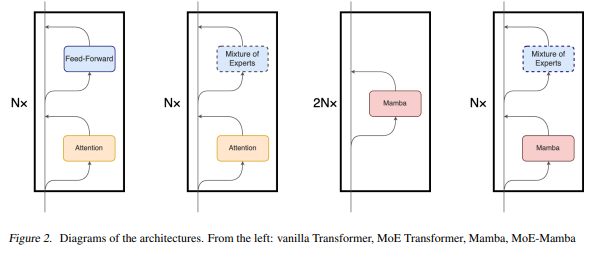
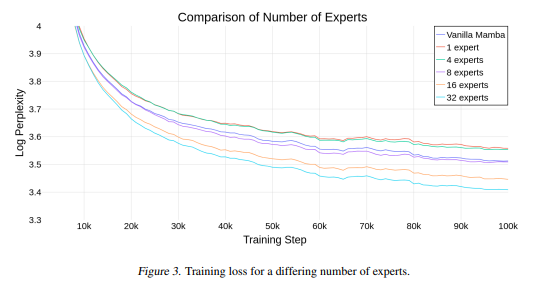




After finally having a chance to test some of the new Llama-2 models, I think you're right. There's still some work to be done to get them tuned up... I'm going to dust off some of my notes and get a new index of those other popular gen-1 models out there later this week.
I'm very curious to try out some of these docker images, too. Thanks for sharing those! I'll check them when I can. I could also make a post about them if you feel like featuring some of your work. Just let me know!