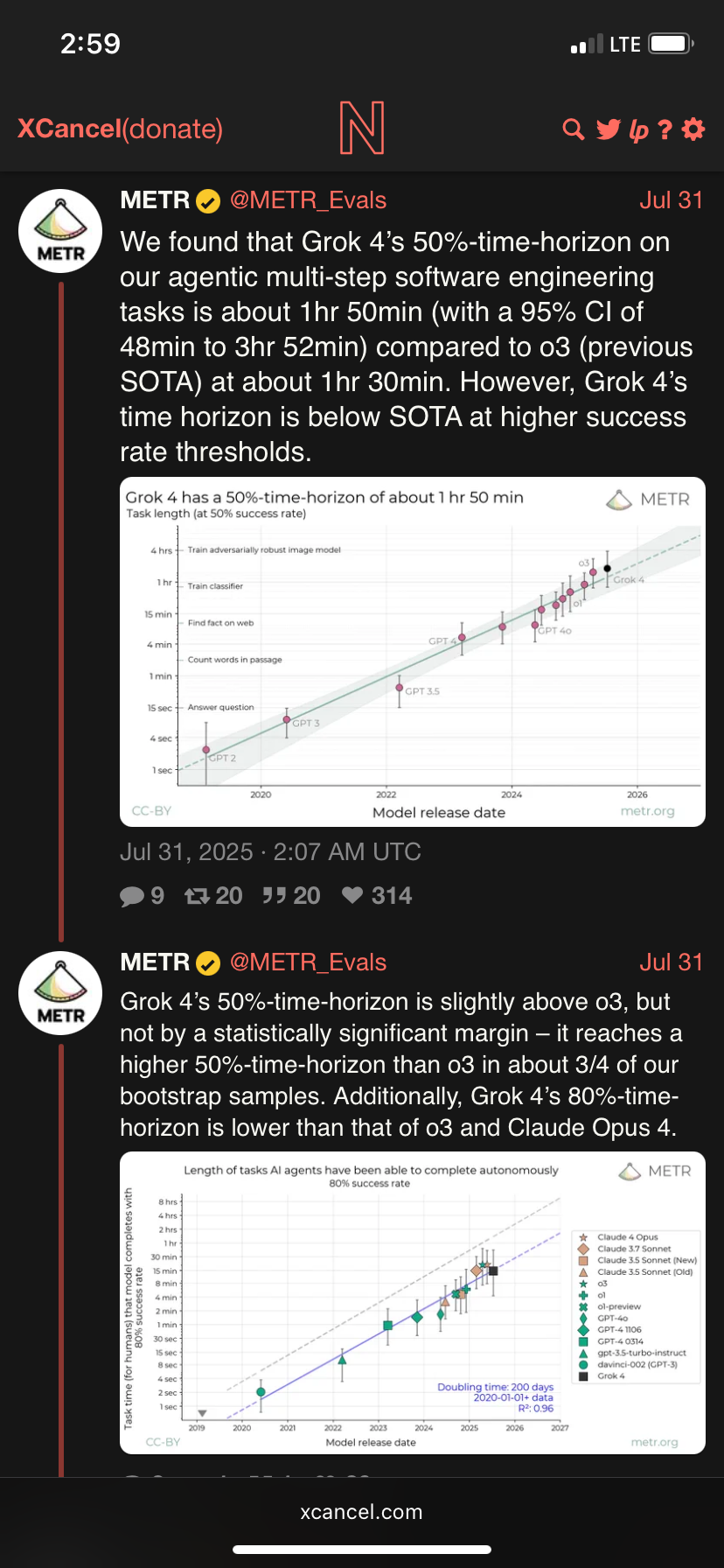
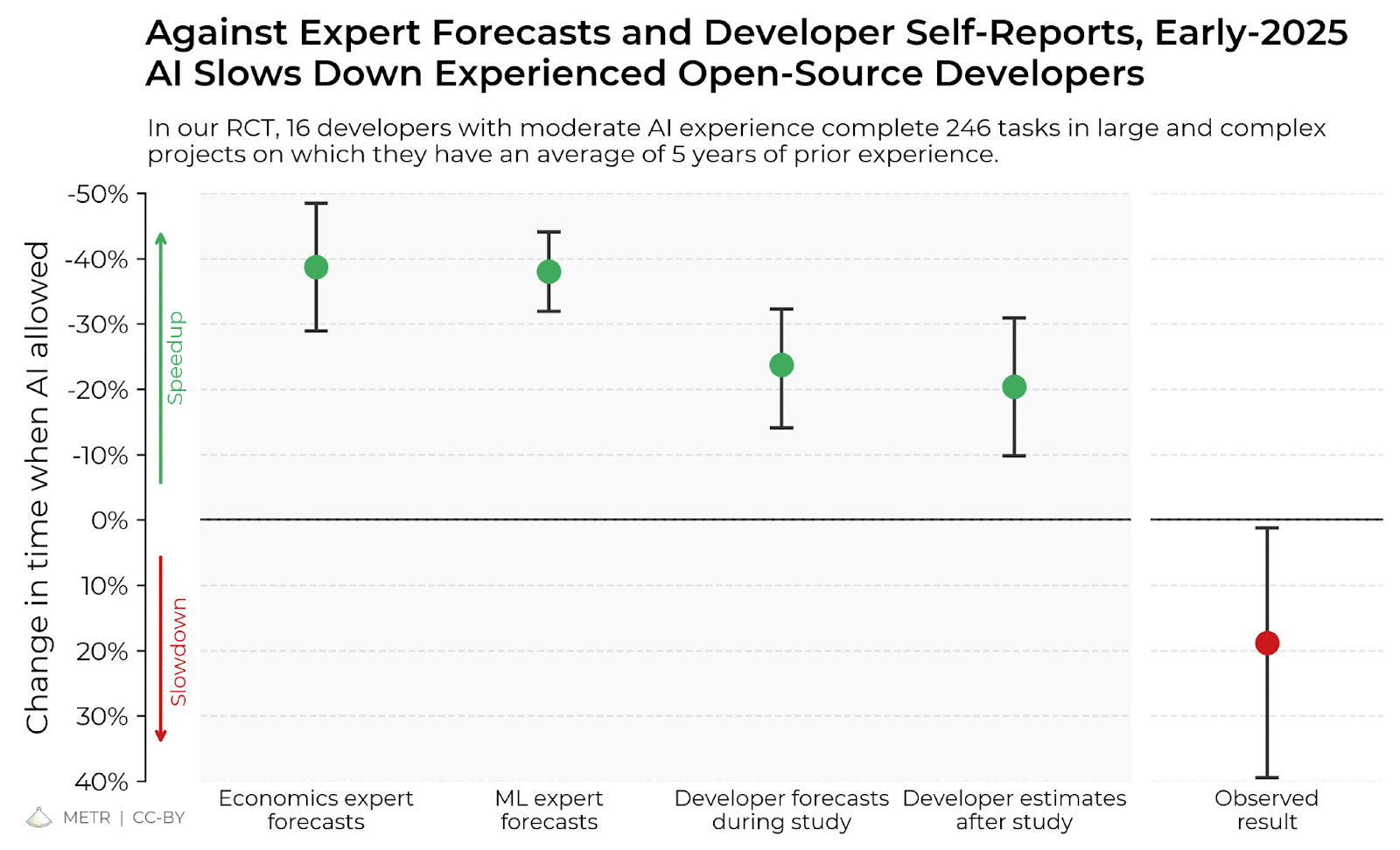
METR once again showing why fitting a model to data != the model having any predictive powers. Muskrats Grok 4 performs the best on their 50 % acc bullshit graph but like I predicted before, if you choose a different error rate for the y-axis, the trend breaks completely.
Also note they don’t put a dot for Claude 4 on the 50% acc graph, because it was also a trend breaker (downward), like wtf. Sussy choices all around.
Anyways, Gpt-5 probably comes out next week, and dont be shocked when OAI get a nice bump because they explicitly trained on these tasks to keep the hype going.

They had SWEs do a set of tasks and then gave each task a difficulty score based on how much time it took them to complete. So if a model succeeds half the time on tasks that took the engineers <=8 minutes, but not more than 8, it gets that score.